


Sometimes the code really is unmaintainable and non-upgradeable. Other times, it might just be old and written in a technology that’s dated or deprecated. Learning how to work with legacy code is a skill in itself. Here’s our playbook for modernizing that old PHP project.
Incremental software development and modernization
Incremental software development is the way mature teams build a product. It means that any changes are very small. So small you can barely see them. Of course, these changes should also be deployed as soon as possible.
So, what does that have to do with modernization? Well, ideally, once your app is in a good state, you are constantly making small changes that allow it to continue to function. Update a dependency here. Rename a variable there. Remove an unused method, and so on.
By making tiny yet methodical changes to your system, its health will improve and then the next time you need to add new functionality, it will be easier to do so. This is the best way to avoid a software rewrite.
A software rewrite should only occur when you need to build a new product. That happens when your audience has changed or the problem you are solving is different. There is one other case: when you must change technology because of a paradigm shift.
For instance, if you once had a rule-based recommendation system and you want to introduce machine learning, this is a very valid reason to start a new project.
So now that we know what we’re talking about, let’s get started.
The mindset for incremental improvement
The first thing that’s needed to successfully apply incremental changes is a new perspective. This is one way that we gauge the difference between senior developers and those who haven't quite gotten there yet.
Rule 1: Ship constantly
Because incremental improvement is about getting software in the hands of users, we need to start by delivering constantly. We aim for several deployments per day, preferably to production. Understandably, some industries are regulated or other situations prevent this from occurring — it doesn’t make sense to deploy new versions of your mobile app every day.
How can you ship constantly? It’s all about that continuous integration and continuous delivery pipeline (CI/CD pipeline). Whenever we join a project, this is one of the first things we look at.
Can anyone on the team press one button and ship code?
If you answered “No,” then you’ve got your first task. Get a CI/CD pipeline running so that it has one passing test (more if you’ve already got them) and automated that ships code to a staging environment.
After you’ve got the bare bones of a pipeline, you can continue to improve it by adding tests, linters, code formatters, and other tooling that increases the confidence level of the team.
When should the CI/CD pipeline run? We like systems to run automated tests and static analysis when pull requests are opened. This helps code reviewers understand the quality level of the submission. Pre-commit hooks can be useful to automatically format and lint files that have changed.
Containerization can help here. A setup using Docker empowers engineers to easily match local development environments with test, staging, and production. This ensures that tests run the same way on every machine, further protecting the product from error.
Rule 2: Ship quality constantly
Now that you are shipping constantly, you need to ship stuff you know is working. So far, you’ve encountered bugs but you’ve been able to quickly solve them since you just shipped that code so it’s fresh in your brain.
Now it’s time to add a bit more maturity to the process so that you can find the bugs before customers do. This means testing. Tests are an important part of incremental improvement, especially the refactoring that occurs as a part of it.
I don't know how much more emphasized step 1 of refactoring could be: don't touch anything that doesn't have coverage. Otherwise, you're not refactoring; you're just changing shit. — Hamlet D’arcy
So let’s start with the basics. How many tests should you have and what kind of tests should they be? The Test Pyramid answers these questions. Created by Mike Cohn in Succeeding with Agile, it’s a great metaphor for how to manage your test suite.
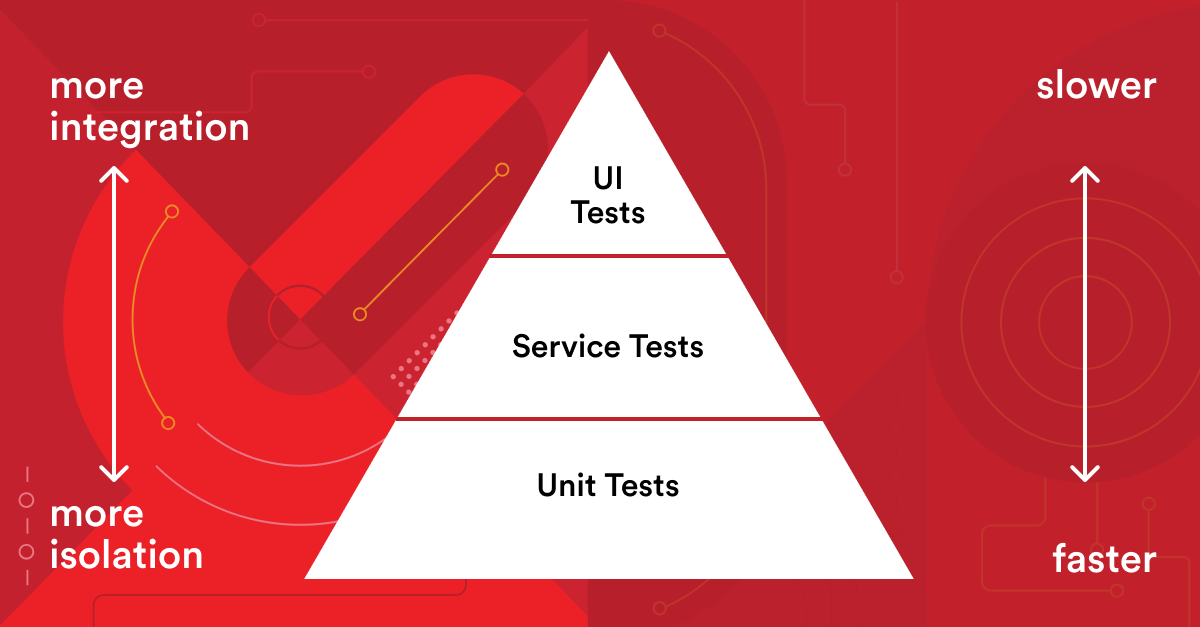
You can see that the base of the pyramid is fast-running, isolated unit tests. Next up, service testing (also called integration or component tests) is a moment when different individual units get assembled to function together. Finally, there is a sprinkling of UI tests (end-to-end tests) since these are slow and expensive.
When you are adding or modifying code, check if it already has some tests. Do these tests cover the edge cases or just the happy path? Can you add a couple more tests so that it’s easier to introduce changes? Is this bit of code completely untestable? That’s a sign that something needs to change.
When modernizing a codebase, you’ll want to move towards Test Driven Development. In short: add a test; see that it fails; make changes to the code; verify all tests pass. Rinse and repeat.
This seems a bit extreme, but by creating changes in this way, you’ll know that the new code you are writing does what you think it does. And as your test suite grows, you’ll also see that nothing else breaks.
Writing quality code requires craftsmanship and some teams skip tests. This is akin to a doctor who doesn’t wash their hands before surgery. Sure, it’s faster but you’ll end up with big problems later.
Rule 3: Ship the right stuff with quality constantly
Now that you are shipping quality code constantly, it’s time to ensure you are building the right stuff. Remember that you are writing code for humans, not computers. Humans will be reading the code (your colleagues) and the functionality is used by humans (your customers).
When updating the antiquated code, the team can begin by gathering some metrics about current usage. It doesn’t make sense to invest time in modernizing functionality that isn’t used. If one percent of customers use a particular feature, consider removing it instead. Smaller code bases are easier to maintain.
When making changes, a key principle to remember is YAGNI — you ain’t gonna need it. When making decisions about abstractions and generalization, focus on what the current problem is.
For example, imagine a simple invoicing system that allows users to upload a file. Start with the basics, a service that stores the file on disk. There is no need to abstract the storage mechanism initially.
In the future, the requirements might change; then this code will get refactored. And the key bit is you’ll have more information at that point, when the change actually needs to occur. This makes the solution better overall.
Ditch the unnecessary complexity. KISS, Keep it simple, stupid!, follows the same advice. Over-engineering is worse than under-engineering. This is because, later on, the under-engineered version is easier to modify and think about.
Another way to ship the right stuff is to Don’t Repeat Yourself (DRY). This principle is sometimes overapplied. Remember, this is really about business logic, not specific code snippets. Sometimes, the best thing to do is to repeat some code in order to avoid coupling components that should be independent of each other.
And stand on the shoulders of giants. Don’t reinvent things that already exist. Need a billing system? There’s a tool for that. Need a ticketing system? There’s a tool for that. Need to capture user feedback? There’s a tool for that. Need a feature flag system? There’s a tool for that.
You get the idea. Be the glue that holds existing systems together. Again, you’ll save time and money with a smaller codebase. Reinvest those savings into improving the core product.
Finally, when facing a tough choice about how to develop or refactor a piece of code, follow this invaluable advice.
for each desired change, make the change easy (warning: this may be hard), then make the easy change — Kent Beck
Incremental improvement via policy changes
Certain policies help engineers apply updates in a methodical and consistent way. Here are the ones we recommend each team should adopt.
The Scouting principle
Although the organization itself has a history of bigotry, the founder of Boy Scouts of America, Robert Baden-Powell, conveyed an inspirational point in his Farewell Message.
Try and leave this world a little better than you found it, and when your turn comes to die, you can die happy in feeling that at any rate, you have not wasted your time but have done your best. — Robert Baden-Powell
We apply this principle to our work each day. For instance, when reading a class, if there are magic numbers, it’s easy to extract those to constants and send a pull request. Or rename confusing variables. Simple small changes like this keep code legible and easy to work with.
Zero bug policy
This policy is often misunderstood by non-technical people, so take care when introducing it. Zero bug policy does not mean that there are no bugs in the software. It means that the number of detected bugs is never increasing.
For example, say the team currently has 50 open bugs in the issue tracker. A new one is discovered. It should be prioritized, or — if it’s a difficult and time-consuming problem — take a different bug off the pile and fix that one instead. The total number of open bugs remained the same.
Eventually, the team will find time and space to whittle away at the pile. Some of the more complex issues will be redesigned, refactored, or removed. Test coverage will increase and eventually, the team will reach zero open bugs.
How can you build a house on an unstable foundation? Any time new functionality is being built, the team needs to spend time refactoring and reorganizing the existing code. We recommend spending roughly 50% of engineering effort on maintaining and improving the quality of the codebase.
Tooling policies
We do not advocate forcing team members to use specific tooling. Instead, team members must be responsible for mastery over their tools. By building up expertise with certain IDEs and frameworks, their efficiency and confidence will increase.
This allows you and your colleagues to rely on your tooling to do the heavy lifting. For instance, in PHPStorm, did you know that you can easily extract constant values? Do you also know the keyboard shortcut to do this?
If you deeply understand how your tooling works, you will know what is safe to automate. Then, you can quickly serialize simple changes. You’ll have full confidence in these changes since you understand exactly what’s changing.
Pull requests and documentation
Another key policy is creating consistency around pull requests and documentation. Importantly, pull requests need to be limited to just a few changes. On our teams, large pull requests are instantly rejected by team members.
Coupled with a good description and atomic commits, it should be possible to review pull requests in just a couple of minutes. Require the team to describe what the problem was, why this particular solution was chosen (trade-offs compared to other options), and perhaps even a gif showing off the results (if present in the user interface).
More complex changes can be chained (also called stacked pull requests), where one pull request points to another. The first pull request points to the main branch; the second one points to the first pull request; the third one points to the second one, and so on.
Testing policies
The last policy to be implemented is that the amount of code coverage never decreases. If new code is added, new tests must also be added. Start with focusing on the core business logic and in a short time, you’ll have the vast majority of it covered. This also encourages the team to simplify code and remove functionality that is not used.
Modernization strategies
Now that you have the right policies in place and the right mindset, it’s time to apply a specific strategy to refactoring. Each project and section of code is different, so there is no magic bullet.
The Strangler pattern
The name sounds grim, but it comes from the Strangler fig, a plant that overtakes a host tree, slowly sapping it of energy, often resulting in the host’s death. The pattern works the same way, starting small, taking on more and more responsibility, and eventually completely overtaking the underlying technology.
One of the best ways to apply this pattern is to start a fresh codebase — we prefer Laravel. Create a folder called Legacy and drag the old project in there. Configure Laravel’s router to pass all requests through to the legacy application.
Boom. Now you’ve got an encapsulated project. You can slowly extract functionality to the Laravel project, domain by domain, service by service, model by model. If you’ve got end-to-end tests, you can also be sure that unexpected side effects are limited.
Delete antiquated code as functionality is extracted to Laravel (using all the advantages the framework offers such as a modern ORM, validation, and error handling). Eventually, you’ll be able to fully remove the last bit of code and delete the Legacy folder completely.
Façades, Adapters, and Anti-corruption
This approach is often used with a dedicated API layer. Suppose there is an antiquated API; maybe it’s even using XML SOAP technology. In order to modernize this, it would be quite difficult to introduce new changes alongside the existing code.
Instead, create a new API and put it in front of the old one. Clients can then update to a modern stack (JSON and REST/GraphQL) and point their requests to the new API. The new API translates (adapts) those requests into XML SOAP and passes them along to the old API. When it gets data back, it reverses the translation and sends it back. Now you’ve got an adapter.
A facade is basically the same thing but generally refers to a system that also simplifies requests. Suppose the old system requires three calls to do something. You can capture all the necessary information as a single request with the intermittent layer, then perform the three calls on behalf of the user. Get the results and pass them back to the requestor. Your adapter is now a facade.
Another scenario is when the base API has errors. You don’t want to correct those errors directly since some clients might rely on the misbehavior. In the new API, you’ve fixed them during the translation process. Congrats, your adapter also includes anti-corruption.
API versioning
What version of the API are your customers using? Treat the current version of the API as version 1. There’s some debate about the best way to handle this technically. Regardless of the solution you end up with — preferably URI Path and/or Content Negotiation — you’ll want to follow semantic versioning.
As you introduce breaking changes, you’ll update the versioning. Then, you ask clients to update. If there are many clients or you don’t control all of them, this quickly spirals out of control.
When taking this approach, you’ll need a release management plan. Think about software that has versions such as operating systems, programming languages, and major frameworks.
Define a deadline when updates will stop (next month), when the system will stop receiving security patches (3 months), and when the system will become unsupported (6 months). You can also include a long-term support version (LTS) when you hit a big milestone.
Dependency management
A major difficulty in updating antiquated code is managing dependencies. Many times dependencies are checked directly into the codebase and haven’t been updated in years. Worse yet, there might be multiple versions of the same library or even customized changes.
If end-to-end tests are in place, it becomes easier to manage dependencies. Updating that old version of jQuery will probably break some things. If you have end-to-end tests, you’ll be able to find out what broke, instead of relying on your customers to tell you.
Once everything is up-to-date, you can enable Dependabot or a similar service. This tool will automatically check dependencies for updates and send a pull request when it finds them. You can even configure another bot to automatically merge the pull requests if your tests pass — an easy way to keep the system patched.
Microservices
What better way to start an argument than to discuss microservices? In our experience, there’s a time and a place to use a microservice architecture; however, we also feel engineers have jumped to this approach a little too readily.
Some baseline rules are:
- The number of team members must be double the number of microservices — This allows for enough knowledge sharing and reduces the risk of key non-replaceable personnel.
- Data is separated — Think about how services affect one another and the types of data they need to share. Sometimes you’ll find a large overlap which is a hint that you want a monolith rather than microservices. The data in microservices is separated into separated stores. This means data can get (purposefully) duplicated.
- Microservices are single services — They have to have one specific concrete thing to do. Don’t try to force a bunch of functionality into one service. If you program with Symfony, or a similar MVCS, you’ll have a leg up here.
Without violating those rules, can you pick a part of the legacy code and extract it out to its own service? Yes? Good. Do that. Then rinse and repeat. You’ll find yourself with a greatly simplified codebase. Eventually, you’ll be left with code that can’t go into a microservice. Find another way to deal with it.
Should this specific code be modernized?
Code smells are a symptom or heuristic that something can be improved. They are an excellent way to identify code that might need to be refactored (but not always!). According to Refactoring Guru, they fall into several categories.
- Bloaters are sections of code that have grown in size (usually over time).
- When OO principles are misapplied, you’ve stumbled upon Object-oriented abusers.
- Change is hard. Change preventers make it harder.
- Sometimes you can just throw code away to make it easier to comprehend, less complex, or more efficient. This is the hallmark of Dispensables.
- Couplers create extra coupling between functionality, often making the code too complex.
Modernization tactics
Now that you’ve identified something to refactor, you’ll need to do the actual refactoring. There are some specific tactics you and your team can apply to keep things on track. Remember, you need to make purposeful, incremental improvements.
Horizontal versus vertical refactoring
Basic refactoring includes developer experience improvements such as: renaming variables, methods, and classes; removing unnecessary code comments, dead code, and todo statements; and introducing constants and class variables in the place of magic numbers and hardcoded values.
When this picks up in complexity, you’ll have multiple choices about what to refactor. For instance, suppose you have multiple code blocks in the same method that you want to convert to a collection of value objects. But you might also need to take a parameter and move it higher or lower in the call stack.
If you handle all the value objects first, this is horizontal refactoring. If you deal with the parameter first, this is vertical refactoring. Pick one and do it all, then come back to the other. Avoid doing both refactors at the same time.
Avoiding bulk changes
One way that refactoring quickly gets out of control is when one change needs to be applied across the entire codebase. This occurs when the team decides to use a different approach than they have before, such as when changing how to handle null values and validation.
The best approach involves limiting the refactor to the specific, current section of code but renaming methods in a way that reminds the entire team to update the relevant bits during scouting exercises.
Continuing with our example, if a method rename changes the name of an object without null safety, it might not be possible to update the method without then fixing all the other places where it’s referenced.
Instead, start by renaming this method to dangerousRename. Commit that. You’ll see that in all the situations where the method is called, it’s fairly obvious that a change is needed.
Next, create a new method where the rename occurs safely. Call this method rename and you’ve successfully improved the codebase without spending hours on a bulk change.
A rewrite by another name
Another approach is to use feature flagging to encapsulate specific functionality that needs updating. For instance, if a class is generally structured well, but one method has high cyclomatic complexity, you can use branching and flow control to modernize the method.
Start by adding a new feature flag; then ship it in a disabled state. Next, rewrite the complex code in a simpler way. You can use the feature flag to thoroughly test this branch in a safe, testing environment.
When you deploy to production, slowly deliver it to a larger and larger percentage of customers while keeping an eye on your exception monitoring tool (we like Sentry). Once you get to 100%, it’s time to remove the feature flag and the legacy code block.
Automated refactoring and restructuring
Relying on tooling is an important aspect of refactoring. PHPStorm has built-in refactoring functionality and, if that’s your IDE of choice, you should get very familiar with it.
Variable name changes, method extraction, and namespace changes are totally automated and easily applied. Remember, you should play around with these options to understand how they work in detail. Master those tools!
Another approach is to write code that does refactors for you. One example is Rector, an open source tool for instant upgrades and refactors. You might even get lucky and complete the upgrades without having to write any code. For instance, Rector can take a PHP 5.3 codebase and automatically upgrade it to PHP 8.1. How does that sound?
In more complex cases, you can write plugins to Rector that will help you with the problem at hand. We once had a project with four separate repositories. Unfortunately, there were some conflicting namespaces, so we had to dig deep to find an easy way to merge them. Fortunately, it was easy to write a Rector plugin that did the heavy lifting for us.
If you are looking for more ideas about how to apply Rector to your projects, check out Rector — The Power of Automated Refactoring by Matthias Noback and Tomas Votruba.
Going forward
Now that you understand how to modernize your PHP project, it’s time to roll up your sleeves and get busy! But don’t take on too much too fast. We find the best teams split their time around 50/50 between feature work and keeping the system running.
This translates into a rhythm of working on functionality but allocating extra time (double!) so that the team can also make other improvements alongside that customer-facing change.
It’s never too late to start incrementally improving your product. Start now before you have to rewrite your product from scratch, something that almost never works.









