


You’ve heard the term technical debt but you couldn’t find out exactly what it is or why it’s important. Perhaps you’ve heard your software engineers discussing it and you want to understand why it causes so much trouble as they work on your product.
We spoke with Jonas Drieghe and Michal Karnicki (madewithlove), Zvonimir Spajic (a software consultant), and Mathias Verraes (Aardling) to find out exactly why tech debt is so important. They also told us how to handle tech debt along with legacy code in bronwfield codebases.
Technical debt is the trade-off because
things can’t be built perfectly.*
* Technical debt is the other side of: “Better shipping than perfect”. Things can be built perfectly, but that context and systems evolve so quickly that it becomes hard to define what perfection is. More on this below!
There are a few things we have learned over the years, after helping multiple technical teams of startups and scaleups in the SaaS industry. And as with most things in software engineering, it boils down to striking the right balance and making the right compromises.
Here’s what we think you should know about technical debt; however, keep in mind this is a sophisticated and very deep topic so the information below is just a drop in the ocean.

Definition: What is Technical Debt
What is tech debt?
🏧 The ATM — a very simple explanation
Let’s start by describing what technical debt is with a commonly used metaphor, the ATM. The machine gives you money after entering your card, making a selection, and submitting your pin. Where would technical debt live in the model of the ATM?
If the interface is not fully updated, there might be functionality not working or accessible anymore. Or when users start using cards with newer chips, the machine might not support it. Your technical team accepts limitations whenever they ship a new version of the software.
In the next version, they might create a better interface, make the ATM work with Stripe integrations, or create another language for international users, for example.
This is where technical debt comes to life: when working on the first version, the team might have decided to work with hard-coded card types and avoid translation keys to save time.
Now adding additional functionality such as multilingual support is close to impossible without having to rewrite major parts of the software from scratch. Hello, technical debt.
⚖️ Technical debt is a conscious decision and a tradeoff
Does code need to be perfect? Let’s all agree on one thing before we dive deeper into the world of technical debt. No one can build the perfect system. Building software is about creating abstractions and recreating the world in code is simply not possible.
Because of this, technical debt will always occur in an ever-changing and evolving system, one that mimics the real world. So every technical team will have to deal with, cope with, and manage technical debt sooner or later.
🏦 Debt accrues interest — you can’t ignore paying off the (technical) debt
As the name technical debt suggests, at some point in time your team will have to pay back the debt. You know how interest on financial debt works.
In general, with any form of technical debt, the longer it exists, the more complex and bigger the debt will become. Addressing technical debt early on is much less painful — and less costly — than doing so months or years later.
🦾 A collective responsibility to managed systems
Engineers and team leaders must monitor how much technical debt they acquire and manage it consistently. The product should lean on the experience of the engineering team to determine which debt needs to be addressed and which is fine to stay a bit longer (perhaps because a module will be removed in the near future).
It’s technical debt, so technical minds are required to translate it so that non-technical folks can understand the challenges and collectively make the right decisions and trade-offs.
Often, but not always, the choice to deliver on time causes product and engineering teams to make trade-offs. Unfortunately, these trade-offs are rarely revisited and they often become debt the moment they are introduced.
🚢 Story of startups: ship now!
Ship fast! Ship often! Let’s speed things up and catch momentum.
Every startup battles timings and deadlines because they all move quickly. A mistake is often made by cutting quality in the software development process.
Many startups build functionality that is not essential, creating problems when the product is starting to pivot or evolve to a newer version. The software becomes harder to maintain, document, and upgrade. Eventually, software development will slow down and open the door for technical debt to slip in by cutting corners.
Also read: A founders guide to understanding technical debt
Other types of technical debt and specific forms of tech debt
But there is more. Technical debt occurs not only in the codebase or in the code itself. A technical team in the SaaS ecosystem can also face other types of technical debt. These are some of the more common types of technical debt when working with software:
- Architecture Debt
- Build Debt
- Code Debt
- Design Debt
- Documentation Debt
- Financial Debt
- Infrastructure Debt
- Requirement Debt
- Test Automation Debt
- Test Debt
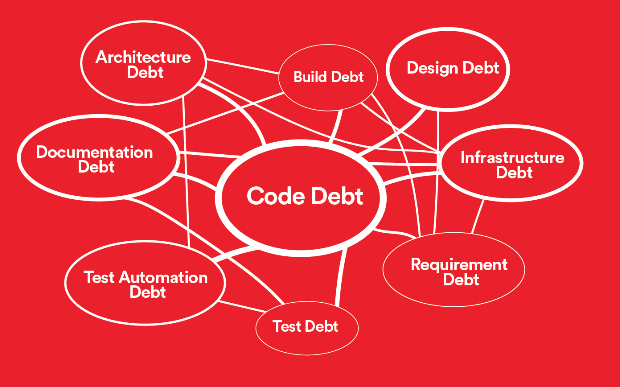
All of these types of technical debt are very intertwined. A novice engineering team, lack of well-defined (and continuously refined) processes, or missing documentation can all cause a cascade of debt, impacting design, architecture, and code.
The difference between technical debt, legacy code, and code rot
Technical debt
Technical debt is the outcome of the development team’s actions which will need to be reworked or refactored in the future. Technical debt can occur due to changes in the environments, badly written code, or deliberate choices. Usually, (undeliberate) technical debt is the result of prioritizing speedy delivery over well-written code.
Legacy code
Oftentimes mistaken for one another, legacy code and technical debt are not exactly the same thing. They look at the same subject, but from a different perspective.
Legacy code is really about code that is not actively living. It might be used in production, but the day-to-day work on it has ceased. Traditionally, legacy is frustrating to work on because the team has improved since writing it.
Any newly learned best practices are probably missing. The most common frustrations when working with a legacy codebase are: missing documentation, a lack of comments, setup difficulties, deprecated technology and libraries, ugly spaghetti code, or dependency hell.
Sometimes, legacy is perfectly fine. If it’s doing what it should be doing, then the code is automatically updating, well documented, and not causing any bugs. We’d still call it legacy code because it simply has not been touched for a (long) while.
Code rot
The concept of code rot is quite similar to technical debt, but again, from a different angle. Code might be perfectly fine and work without hassle, but because of the environment the code lives in, it might malfunction.
Compiling and running code might stop working overnight without anyone making changes. This is because the environments are never static. There are always newer compilers, server upgrades, patches of the operating system, updates in third-party packages, or even framework upgrades occurring. Changes in browsers or mobile phones might also cause code to stop working.
Because most of these changes are small and subtle, engineers will not notice minor warnings and bugs if they are not prepared. But at one point in time, the accumulation of these little changes will result in a breakdown (critical bugs!) of the software. This gives us the feeling that the code itself is rotten.
How is technical debt created?
Classifying technical debt
Technical debt oftentimes becomes an umbrella term in the industry for both poor quality code as much as the code that is a result of trade-offs. When talking about technical debt, it’s good to understand it can occur in myriad forms. Let’s break it down a bit.
1. Deliberate versus accidental technical debt
Steve McConnell made the distinction between intentional and unintentional tech debt in the paper he wrote back in 2007. In short, intentional technical debt appears when product and engineering teams deliberately choose to improve codebases and features later. In other words, when the foundations are laid correctly, full functionality will come later.
Unintentional technical debt appears accidentally, often because of mistakes, bugs, misunderstandings, or inadvertent changes in the functionality of the app. The code quality simply isn’t good enough or future-proof; it should be updated or refactored soon.
2. Prudent versus reckless technical debt
Hopefully, when creating code, the system is well designed. Sometimes things don’t go as planned and there is a future-thinking choice to be made. This is the definition of prudent technical debt. On the other hand, some engineers like to dive into coding a solution and are reckless with their decisions.
This is how Martin Fowler thinks about trade-offs in his Technical Debt Quadrant. The quadrant has two axes, one from reckless to prudent and one from deliberate to inadvertent (accidental).
Classifying technical choices in this way shines a light on inexperienced teams that just keep shipping without thought. Contrast that to ones that know what is going on and deliberately make choices. The latter often comes with seniority in software development, which we’ll touch on later. Thanks for the insights, Martin Fowler.
3. Managed versus unmanaged technical debt
At madewithlove, we like to talk about managed vs unmanaged technical debt. Avoiding technical debt is impossible, but it can be managed to a degree. There is a difference between the technical debt that is introduced intentionally and with reason, as opposed to debt that is introduced due to negligence and poor design (on multiple levels).
What is the most common cause of creating technical debt
We constantly see the following pattern at the companies for which we provide technical strategy services. These three steps are a sure-fire way to create unmanageable debt.
Step 1. Say Yes
Start by never allowing your engineering team to say no. Every single request, every single feature, must be implemented in exactly the way the CEO or the product team wants. Immense pressure is put on engineering teams to agree to the specifications on hand.
At madewithlove, we often joke that we offer No-as-a-Service (NaaS). It’s imperative that those writing code can pump the brakes on an idea or functionality. In order to do this, psychological safety must persist throughout the organization. In this way, the team will feel comfortable pushing back.
Step 2. Impose unreasonable deadlines
Once the work has been agreed upon, now it’s time to set an unrealistic deadline. After all, how hard is software development work really? With this many engineers, it should be easy to add that new functionality.
You’d probably expect tight deadlines to be a number one reason, but we like to think it’s the development team’s responsibility to inform the decision-makers about unrealistic deadlines and stand up against them.
There are two types of deadlines, according to Douglas Squirrel and Jeffrey Fredrick, the authors of Agile Conversations. Rocket ship deadlines are specific like launch windows. You either hit it or you have to wait two years for the planets to align again.
Starship deadlines are like Star Trek. You are on your way to Farpoint Station when you get interrupted by something that deserves your full attention. You’ll make it there eventually though (or will you?!).
Engineers should question Starship deadlines since they are arbitrary. What you discover along the journey is the more important thing. But treat Rocket ship deadlines with the weight they deserve. Honor them and communicate openly and honestly so your team doesn’t miss the launch window.
Step 3. Cut corners (documentation and tests) to meet the deadline
When the pressure is on, it’s time to cut documentation and automated tests out. Then they can build one more feature this sprint. Surely.
We’ll go a bit deeper into tests later on, but we can already state that a lack of tests is often a clear indication that there is technical debt in the codebase. Difficulties will occur when shipping code without any proof that it meets requirements (and edge cases).
Documentation is everything. Clear definitions, proper READMEs, well-structured communication, naming conventions, feature passports, and changelogs… it’s all part of the written communication around your product and you have to make sure it’s good and streamlined and regularly updated.
Tests and documentation are a developer’s way of saying “trust me on this.” They are a sign of craftsmanship, and if they’re missing, it’s hard to extend that trust.

How to avoid technical debt in software development
To avoid technical debt from the get-go, speed things up by only building the most important features. Build functionality with precious care and detail, but only work on the stuff that proves the business model is a well-validated idea or is the crucial core mechanic for the stripped-down product value.
This is general advice that will work for most startups, but sometimes the knots will be more complicated to untangle. Here are other ideas on how to tackle technical debt.
1. The best code is no code
The best developers are the lazy ones. Our senior software engineers say that the best code is no code. If we write code to achieve our goal, we attempt to write the minimum amount to satisfy the requirements. Whichever lines of code in the codebase don’t serve the purpose of satisfying those requirements — as simply as possible — are extraneous and should be removed.
2. Cutting scope and proper shaping
One way to avoid introducing debt is cutting scope, such that a limited feature can be shipped with quality results yet still be maintainable. Two ways of defining a good scope for your particular case are by using Feature Passports and Double Diamond Design.
🛂 Feature Passports
Feature passports are a way to document problem research and proposed solutions. Feature passports are the Wikipedia articles for new functionality. They contain all relevant information in a concise way.
Feature passports do not always go in-depth on any topic but can link to the relevant information instead. After reading a feature passport, everyone should understand what the problem is and why it’s important.
💎💎 Double Diamond Design
Double Diamond Design is a design process model. It has four stages: Discovery, Definition, Development, and Delivery. Together, these stages work as a map designers can use to improve the creative process by organizing their thoughts.
In short, you first acknowledge and describe the problem and define metrics that can measure success. You will refine the problem definition and validate it with customers via user interviews.
Then, you will break that bigger problem down into smaller chunks, for the right target audience, so it’s tangible for your development team to research and prototype. In the delivery phase, the new functionality will be refined and shipped, tested, and measured.
3. Class names
Another, relatively easy way of managing debt is intentionally naming classes that explicitly indicate they are temporary. Reading the code should scream that this part is temporary.
It should not become a dependency of other functionality and should be removed (or heavily refactored) just as quickly as it was introduced to the codebase.
4. Seniority
The quality of decisions often correlates to the experience of a team. Do they, as a group, understand technical debt in all its shapes and forms and how it plays into the product?
Software engineers with more experience are more mindful and intentional when they have to introduce technical debt. Of course, everyone does their best to avoid doing so, but sometimes that is impossible.
We also believe seniority of an individual is impacted by their experience with older systems. If they spent 10 years building greenfield products and always left after 1-2 years, it’s unlikely they’ll have felt the pain of technical debt and may not know how to work with it.
5. Thorough and up-to-date documentation
However prosaic it may sound, a more senior team member knows that a TODO comment within the source code will be forever forgotten. Instead, individuals should thoroughly document the reasons why the particular solution was chosen (preferably in proximity to the code containing technical debt) and immediately add a task to the backlog of work to address it… and make sure it doesn’t stay in the backlog for long.
6. Bring in a fresh pair of eyes
It helps to have fresh eyes on a situation. If the codebase has been evolving for many months (if not years), it’s easier to challenge the status quo. Pair programming is one way to do this internally. Temporarily bringing in a senior freelancer or even a software engineering agency will help, especially if your team is rather junior to bridge the gap when pair programming.
6. Improve the process
Make technical debt part of each engineer’s everyday job. If the existing team is capable, improvements on the process level can give them enough breathing room to finally start tackling the technical debt on a regular basis.
Most people don’t like technical debt and it’s painful when “regular work” doesn’t include managing it. “We’ll address this later” can eventually lead to unsatisfied team members and thus, churn. Make it part of everyday work. More later on product work (build new features and work on functionality changes) vs development work (maintenance, bug fixes, technical debt management).
7. Use the correct data
The product team should have quantitative data reflecting how the product is used and the team can use this to determine which technical debt should be addressed first. In this way, they can focus on the areas which will have the most positive and material impact on the end-users. As always, everything should be done with users in mind.
Even though the methodology is the same as for product work, this should be done in the 20% (or whatever) time by the developers, not the product manager or the product owner. This idea is true only if the reason for the technical debt is strictly technical, of course.
If it is there because the problem is not fully understood, this becomes a team effort, but then you might as well make it product work and put it on the roadmap.
8. Definition of Done
The Definition of Done is an agreed set of items and rules that must be followed before a task can be considered complete. A good definition should be collectively decided upon by the team (and continuously refined). This agreement helps prevent the introduction of non-intentional debt.
This ruleset can be concise or very extensive and can contain more than just code-specific items. A typical definition of done includes checks on the completion of code reviews, staging and testing environment deployments, documentation updates, feature passports, regression or stress test requirements, green lights by stakeholders, and security or usability checks.
Our colleague Mike Veerman talks about Definition of Done in our podcast episode. He also has an opinion on Definion of Don’t.
9. Refactoring
When engineers need to “clean up the mess” in Legacy Land, this is refactoring. Good moments to spend time refactoring legacy code are when there is a critical bug, a total lack of documentation, or when onboarding new developers to the project.
Following the Boy Scouting Rule (leaving the code base cleaner than you found it), breaking code into smaller chunks, and adding tests will greatly help with refactoring — and there is plenty of material out there to learn how to do so.
Another interesting concept is the Grandfather rule. A grandfather clause is a provision in which an old rule continues to apply to some existing situations while a new rule will apply to all future cases. Those exemptions from the new rule are said to have grandfather rights or acquired rights or to have been grandfathered in.
for each desired change, make the change easy (warning: this may be hard), then make the easy change
— Kent Beck 🌻 (@KentBeck) September 25, 2012
Preventing technical debt with tests
Test-Driven Development
If code is hard to test, it is almost certainly hard to maintain. Test-driven development results in highly testable code because it’s impossible to have code that is hard to test if tests are the first line written.
Developers often say “code is only as good as the tests” because it is possible to write poor quality test code (or completely miss edge cases that should be covered), which gives an impression of “quality” (“We have so many tests!”) while the resulting application code base is no better than prototypal code base.
Test coverage
The product can still have good test coverage even if the engineering team has made trade-offs in agreement with the product team. So from that angle, one could say that tests can’t protect from intentional debt that will have to be managed at a later time.
On the other hand, given enough space and no unfeasible deadlines, good test coverage is usually indicative of quality software that will be easy to change and adapt as the product/service grows.
Tests are not the cure for everything but they help limit side effects when changes are made. Tackling and preventing technical debt becomes inherently more sophisticated when good test coverage exists.
“Don’t touch anything that doesn’t have coverage. Otherwise, you’re not refactoring; you’re just changing shit.” – Hamlet D’arcy
Do you need 100% testing coverage?
High test coverage is not an end goal in itself; it is a side effect of good software development practices. Effectively it’s not even something your team should actively think about in terms of percentages. However, if an introduced change decreases coverage, that’s a reason for concern and can be an indication of technical debt slipping into your software.
A great alternative for high test coverage is a high mutation test score. Mutation testing essentially proves the quality of your tests in relation to the actual code that is executed.
How to visualize, quantify, and track technical debt
Tracking technical debt is tricky. There’s not a single metric that will give you the insights you need on the subject, but there are metrics that can provide a general overview of the codebase health like static analysis, test coverage, mess detection, and cyclomatic complexity which are reflected in end-user satisfaction (or lack of thereof).
Tracking technical debt can also be done by implementing good processes within the software development cycle. Here are a couple of examples.
👐 Embracing debt
An analogy made by Kevlin Henney: debt is not necessarily a bad thing. Going into debt gives you a way to buy things today instead of waiting years to save up money. But of course, it’s a slippery slope and you need to be careful not to take on too much debt. The same goes for code. Debt can be good, but it is vital to keep it under control.
🧱 The Wall of Technical Debt
An interesting concept for visualizing technical debt has been created by Mathias Veraes, called the Wall of Technical Debt.
The purpose of the Wall of Technical Debt is not primarily to track debt and fix it. Instead, the core idea is that taking on new technical debt and fixing the existing debt should be a matter of negotiation. Often technical debt is created under the assumption that:
- it’s better to deliver fast,
- it will be fixed later,
- the impact of a better implementation is negligible,
- and that in order to create a better implementation, we’d need to fix existing debt first, which would be too costly.
Sometimes the problem is simply poorly understood. It’s not clear what a better solution would look like. In some cases, the technical debt appears because the context is now different from what it was when the original solution was implemented.
These decisions are usually being made on an individual basis. The goal of a big visual space is to remind the team to make the tradeoff of debt or no debt collaboratively. If that isn’t a physical wall, engineers need to find other ways of making sure these discussions happen before code is written, not during a merge request.
🪟 Quality views
Quality views let us easily understand which system components carry the highest risk. In the end, technical debt is (at least in most cases) not something that can be tackled in a day or week.
It’s pointless to decide on a timebox and “address all technical debt.” It’s an ongoing process to pay off the debt and it should continue to be part of the regular day-to-day work.
Quality views allow your team to visualize this risk of change. To start, create a list of modules within the application. This can be organized along bounded contexts, for instance.
Then for each module, assign a number (and color) from 1 (easy, green) to (5, risky, red). In this way, non-technical team members can easily see which areas of the code will require more effort to work on.
🏋️ Fitness function
An interesting topic in engineering land is building applications by using a Fitness Function. This describes how close the software architecture is to achieve future goals. Usually, it is used in genetic programming (machine learning and the like where descendents move ever closer to a target).
By defining a metric and measuring the current solution’s distance, the team (or algorithm) can move towards it.
One measurement that is commonly used is cyclomatic complexity. This determines how many individual paths of logic exist within a particular class or method. For instance, if there is one `if` statement, then two paths are created.
When nested logic is added alongside for loops and more complex flow control, the system can become impossible for an engineer to work with. This is a classic case of poor design that should be resolved.

Product vs engineer: where’s the gap in technical debt?
Technical debt causes discussions because it depends on the angle that people look at it. In a single team, you can hear the Head of Product saying that 50% of engineering effort is spent on technical debt. While in that same team, the lead engineer will claim they need time to focus on technical debt because more than 80% of their time goes to new features.
Something does not add up here. We see this difference in perception recurring in our audits.
So who is wrong here?
Nobody. And that’s the problem. It’s all a matter of perception. To identify what percentage of work is spent on a certain aspect, the first thing to do is clearly define that specific aspect. Ask a Head of Product and a Lead Engineer to agree on what is technical debt. I dare you.
Where is the 30% gap?
A lot of technical work is essential to deliver a new feature. For example, reworking an abstraction layer to support 3rd party plugins could be considered refactoring away some technical debt. On the other hand, if engineers don’t do it, implementing the functionality will be nearly impossible.
Can we align this with generic technical debt?
The challenge now is to align these perceptions. A good first step to take is to clearly identify areas of technical debt and categorize them. Some things might hurt the team on a daily basis and generally slow down the work. This could be marked as generic technical debt.
At the same time, those pain points should be separated from topics that don’t actively hurt the team but might prevent the system from easily changing. The latter items are called feature prerequisites.
Introducing the roadmap
When working with a roadmap, it’s important to leave room for technical topics. However, these should not be their own items. Instead, for each product functionality, the engineer team should have time reserved to make themselves more efficient — as much as 50% of their time!
Tackling the generic debt can be prioritized when there are no feature prerequisites to work on. This way, the team won’t end up in a situation where they spend 20% of their time on generic technical debt, 30% on feature prerequisites, and 50% on visible feature work. This is where the gap between product and engineering perspective is created.
When is a complete rewrite of your codebase a good idea?
The easy, but certainly not best, answer to technical debt is rewriting your codebase. Let us be short about it. Most of the time, it is not a good idea to start from scratch. It will cost a lot of time and money most startups don’t have.
You will need to juggle investment between the live platform used by clients and the future version. The team will probably also start using a new framework or technology for the rewrite because they have learned from their past mistakes.
This will then result in hiring different profiles and before you know it, you find yourself in a situation that is way worse than when you still had only the initial bad codebase to deal with.
There are times, however, when a company must start from scratch and rewrite the product from the first commit. We believe a rewrite only makes sense in two cases:
- When your target audience (and thus your product) has changed
- When your product is 15+ years old and not working anymore
🧑🏿🤝🧑🏾 🤼 Change of audience & product
After realizing your initial idea and product are not doing what was initially planned, it might make sense to think about a rewrite of your software. When your audience has changed, the need for different features is your number one priority. The problem you are trying to solve has become completely different, offering new solutions for your engineering team to implement.
Plenty of thorough market research and (data-driven) informed decision-making is crucial here. The knowledge you have gathered while building your initial product will allow you to set the proper context for the engineering team. They can then deliver the right set of features quickly on a new platform.
👵🏻 👴🏿 Your product and code are just very old
Sometimes, code and software can simply be too old for the environment that it needs to run in. Security issues, deployment cycles taking way too long, outdated code principles and standards, and unsupported libraries and dependencies are all signs of code that could be abandoned.
Fifteen years of age is seen as very old in software. If the codebase has hit this age without refactoring, today is a good day to throw it away and start from scratch.
Do you need a software rewrite or help with technical debt?
To rewrite or not to rewrite the product is a very difficult decision to make. And don’t make it by yourself! It will greatly affect your business, processes, the technical and product teams, and your company culture.
It will not just be a matter of budget and time.
Ask yourself the following question: can we afford to continue with what we currently have? Realize, that when starting a rewrite, you will end up with two different products that you’ll have to manage at the same time. And ask yourself the question: does code need to be perfect?
We have helped our clients make this decision from a technical point of view after analyzing the product, talking to the people that work with the code, and thoroughly analyzing the technical side of the business.
With our CTO ad interim service, we can be that voice for your business too. Do reach out if you think we should talk or if you need help defining a technical strategy!
Listen to Pulse, our podcast on Technical Debt with Jonas Drieghe
A summary of the podcast episode
In this new Pulse podcast, Andreas Creten talks to his colleague Jonas Drieghe of madewithlove, a senior developer that excels in working in legacy code or legacy systems. They discuss the topic of technical debt in this episode.
Technical debt refers to suboptimal decisions made under the pressure of time, lack of knowledge, or skills, resulting in the difference between what was created and what could have been created in ideal circumstances.
Technical debt is categorized as managed or unmanaged, with the former being covered by tests and allowing for controlled changes. The latter is often invisible and can be like a black hole.
Managing technical debt properly is crucial because it can lead to more significant problems, such as the team leaving, creating a cascading problem that becomes a nightmare for a company. While engineers are closest to the issue, everyone is responsible for solving it. However, management teams often prioritize new features over technical debt, so allocating a percentage of time for engineers to work on technical debt can prevent it from becoming a significant obstacle to product development. It's important to differentiate between legacy code systems and technical debt, as not all legacy code needs to be fixed, but technical debt can hold back progress. The key is to focus on cleaning up the areas blocking progress while introducing new features.
Reframing what those layers actually are
Tech debt is often shorthand for something more specific: a codebase carrying the fingerprints of every era it's lived through. Treating those layers as history rather than mess changes how you approach them.
Read: your codebase is a palimpsest








