




We all know them, search pages which allow you to filter through vast data sets by checking or unchecking filters. In most cases each filter is followed by a counter which indicates how many results will be shown when you apply that filter. Those counters inform the user about their next move before they perform it.
From a technical standpoint, there are a few challenges to those counters. To know the exact count we have to execute the search query again for each filter but with that filter applied. In a complex search application this quickly amounts to a large number of queries. Luckily Elasticsearch, in all its glory, allows us to do this in one query.
Requirements
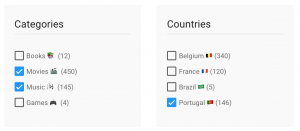
Before we can build anything, we need to understand how we expect our faceted search to behave. This might be different depending on your business case. The best way to explain this is to use an example. Let’s assume we have a search with 2 facets: category and country. Within one facet the filters act as an OR. Across the facets, it acts as an AND. In pseudo query this would look like WHERE (category = 'books' OR category = 'movies') AND (country = 'BE' OR country = 'FR'). This would get all the books and movies in Belgium and France.
The counters need to take the current active filters into account and apply themselves. So if our current active search filter is WHERE category = 'books' AND country = 'BE'. The query to get the count for the France filter would be COUNT WHERE category = 'books' AND (country = 'BE' OR country = 'FR'). This count needs to be executed on the entire dataset, not on the filtered dataset. If you count on the filtered dataset you will bias your counters and they’ll actually be lower than expected.
Writing the Elasticsearch query
Now that we know how we expect it to work, we’ll write it down in an Elasticsearch query. The query would look this if we ignore the counters for now:
{
"query": {
"and": [
{
"terms": {"country": ["be", "fr"]}
},
{
"terms": {"category": ["books", "movies"]}
}
]
}
}For the counters we can use the built-in aggregations from Elasticsearch. Each of our 2 facets are stored as a single field in an index, so we can use a terms aggregation on each of those fields. The aggregation will return a counter per value of that field. Exactly what we need.
{
"query": {
"and": [
{
"terms": {"country": ["be", "fr"]}
},
{
"terms": {"category": ["books", "movies"]}
}
]
},
"aggregations": {
"countries": {
"terms": {"field": "country"}
},
"categories": {
"terms": {"field": "category"}
}
}
}If you were to run that query you’ll notice that the counters are off. The two non-selected countries, Portugal and Brazil, have a counter of 0. While there are actually results if we were to select them (because of the OR inside a facet). This happens because, by default, Elasticsearch executes its aggregations on the result set. Which means if you select France, the other country filters will have a count of 0 because the result set only contains items from France.
To fix this, we need to instruct Elasticsearch to execute the aggregation on the entire dataset, ignoring the query. We can do this by defining our aggregations as global.
{
"query": {
"and": [
{
"terms": {"country": ["be", "fr"]}
},
{
"terms": {"category": ["books", "movies"]}
}
]
},
"aggregations": {
"all_products": {
"global": {},
"aggregations": {
"countries": {
"terms": {"field": "country"}
},
"categories": {
"terms": {"field": "category"}
}
}
}
}
}If we were to just do this, our counters would always be the same because it would always count on the entire dataset, regardless of our filters. Our aggregations need to become a little bit more complex for this to work, we need to add filters to them. Each aggregation needs to count on the dataset with all the filters applied, except for its own. So the aggregation behind the count for France is counting on the dataset with the category filter applied but not the countries filter:
{
"query": {
"and": [
{
"terms": {"country": ["be", "fr"]}
},
{
"terms": {"category": ["books", "movies"]}
}
]
},
"aggregations": {
"all_products": {
"global": {},
"aggregations": {
"countries": {
"filter": {
"and": [
{
"terms": {"category": ["books","movies"]}
}
]
},
"aggregations": {
"filtered_countries": {
"terms": {"field": "country"}
}
}
},
"categories": {
"filter": {
"and": [
{
"terms": {"country": ["be","fr"]}
}
]
},
"aggregations": {
"filtered_categories": {
"terms": {"field": "category"}
}
}
}
}
}
}
}This query finally produces the results and the counters we were after. This is a simple query with only 2 filters but when you have a large set of filters and different types of filters it is easy to lose your overview and allow bugs to sneak in. You might want to look into a package like our elasticsearcher to help you abstract parts of your query so you have a better overview.
Other interesting reads
- Running PHPUnit with PHPStorm
- Why remote is the new workplace – 2022
- The smelly approach to structuring your startup





Member discussion