


Recently, we were looking into some Laravel PHP8 performance issues we were experiencing on one screen of a web application. This screen would show an aggregation of several statistics across the application and would include things like:
- The total number of tickets, grouped by their status (open, closed, …)
- The total number of tickets, grouped by their epic.
- The total number of tickets, grouped by their assigned user and grouped by their epic.
We didn’t initially notice that there were problems because there wasn’t enough data. But as it grew over time and more tickets got created, those problems became more noticeable. In this article, I want to take you along the journey of identifying the problems and how we ended up improving the performance by 98%.
Check out these Laravel Statistics Packages
Identifying the bottleneck with Clockwork
The first step is to identify the source of the problem. We started by creating a database seeder that could create a lot of tickets with various statuses, epics, and assignees. This way we were able to simulate a situation of around 100 tickets per status, spread across 10 different users within a random epic.
The next step was to identify what was happening on that screen by using Clockwork. This is a PHP development tool in your browser that can be used to analyse and inspect HTTP requests, CLI commands, Background workers, etc.
With Clockwork in hand we were able to set a benchmark for ourselves, which was a staggering 10 seconds (in our production environment it was around 2 seconds). What we also noticed is that we were doing close to 4000 SQL queries on that screen alone which seemed very strange.

There were a couple of things in our code that we identified as problematic that lead to this situation, a brief overview:
1. Using Ticket::get()->count() to retrieve the totals of each status
This would mean that all the tickets would first be loaded in memory, combined with a lot of eager-loaded relationships. This led to a lot of time spent on hydrating those records to the Eloquent models.
2. Inefficient retrieval of the amount of assigned tickets per user, per status
In order to retrieve this, we would first query all of the tickets (a second time), then loop through them and then retrieve the tickets for the user again. This could result in a lot of duplicate lookups as a single user could be assigned to multiple tickets.
3. Inefficient retrieval of the amount of tickets per epic
Similar to the previous one, we would first query all of the epics and then find each of the tickets for the epic.
Solving one problem at a time
One of the benefits we did have when working on this problem is that all of the code was covered by an extensive suite of automated tests. This allowed us to refactor things very easily as we could always ensure the build was green and take things one step at a time.
The first improvement we made was to make use of the count() aggregate function of Eloquent. This essentially avoids hydration of models and performs a SELECT COUNT() query instead of retrieving all the records.
Secondly, we reduced the amount of loops and queries needed to query each assignee’s ticket count to start from the list of assignees instead of the tickets. This avoided a lot of duplicate queries when an assignee would be assigned to multiple tickets.
These (in retrospect obvious) improvements had already given us a much better performance. We reduced the amount of queries being performed by 93% and load times were to an acceptable level again (sub 300ms).
The n+1 query problem
However, we were still a bit annoyed by the querying of the amount of tickets per epic and assignees since it suffered from the n+1 query problem. If you’re unfamiliar with the problem, here’s a quick example.
In order to retrieve the counts per epic, we would first retrieve all the available epics, then loop through them and do an additional count of the tickets assigned to that epic. Translated to code it looks like the following:
// SELECT * FROM `epics`;
$epics = Epic::all();
foreach ($epics as $epic) {
// SELECT COUNT(id) FROM `tickets` WHERE `epic_id` = :epic_id;
$amount = $epic->tickets()->count();
}What this means is that as our amount of epics grows over time, so would the amount of queries performed to retrieve the tickets.
Thankfully, there is an easy way to improve this with Eloquent using one of the relationship aggregation methods of Laravel. For the epics, we can query it like so:
Epic::withCount([tickets])->get();
This will include a ticket_count attribute containing the amount of tickets per query, all in a single SQL query:
SELECT
`epics`.*,
(SELECT count(*) FROM `tickets` WHERE `epics`.`id` = `ticket`.`epic_id`) AS `tickets_count`
FROM `epics`We wanted to do the same for the amounts per assignee, but this was slightly more complex since, in our domain, a ticket can be assigned to multiple users. So we ended up having to modify the query a bit, which is possible by providing a callback to the withCount() method.
User::withCount([
tickets => function (Builder $builder) {
$builder->where('status', open);
$builder->whereHas('assignees', function (Builder $builder) {
$builder->where('user_id', '=', DB::raw('user.user_id'));
});
}
])->get();The key takeaway here is to use DB::raw('user.user_id') to ensure the count is scoped to each individual user, without it the total number of tickets would be the same for every user.
The result
With all of these optimisations we:
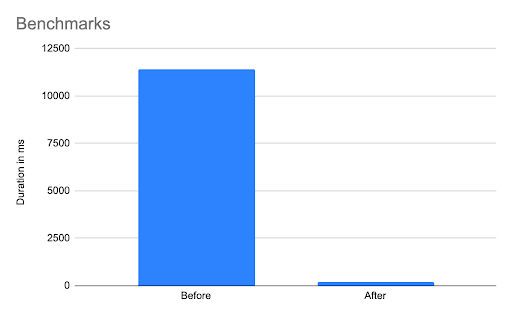
- Reduced the loading time from 10 seconds to 220ms, a 97.8% decrease
- Reduced the amount of queries performed from 3879 to 18, a decrease of 99.5%
That even looks impressive on a bar chart:

ORMs often get met with a lot of criticism when it comes to performance. Hopefully this article proves otherwise and that, with help from the framework and some SQL knowledge, you are able to get to acceptable levels of performance.
My main takeaways are the following:
Having an extensive test suite to cover these calculations proved to be very valuable. It allowed us to refactor the underlying code without having to worry about introducing regressions.
Having good tooling to monitor performance on both production and local environments, especially when combined with detailed traces, help not only with identifying problems but also to measure if the fixes you did actually work.
This was definitely a learning experience for me and hopefully, in the future, we don’t run into these problems again.









