

I’ve always been fascinated by science fiction and the advances of technology. And AI/ML has often represented a huge chunk of that because, for me, it’s the closest way that I, as a single person, can create life and feel like a god.
And that’s really what most of science fiction is about 🤖! I’ve tried a couple of times to get into AI; I’ve read things here and there, watched talks, but none of my attempts really stuck because it always just felt like a feather to add to my cap as a programmer. But then in 2020 something happened: GPT-3 dropped.

Through AI Dungeon, it allowed me to have somewhat realistic conversations and adventures with AI characters, and it entirely changed my perception of the field. I suddenly felt like maybe that fancy realistic AI I was picturing in my head wasn’t that far out of reach.
I felt that if things truly were getting better at such a rapid pace, then it was likely that some decades down the line I’d have either lost interest in web development or that it’d be gone altogether. And when that’d happen, teaching an AI to do it instead was definitely what I wanted to do with my life, so I had better get started now.

So I made a list of the available, fully-fledged courses and jumped into what seemed like the best option at the time: the Kaggle course on machine learning. I picked it because it was free, had no prerequisite, had interactive exercises, and Kaggle itself provides lots of useful resources for AI aspirants such as 📚 datasets, 🏆 competitions, 💬 forums, and so on.
In a short span, I caught up on an incredible amount of Python and machine learning knowledge and, to my great surprise, the more I learned the more I realised that… things were much simpler than gatekeeping idiots had led me to believe 😅.
Unless you work for Google, you don’t need a PHD in Super Advanced Mathematics™ to understand what’s going on or how to create tangible working things that already feel like they have life and intelligence.
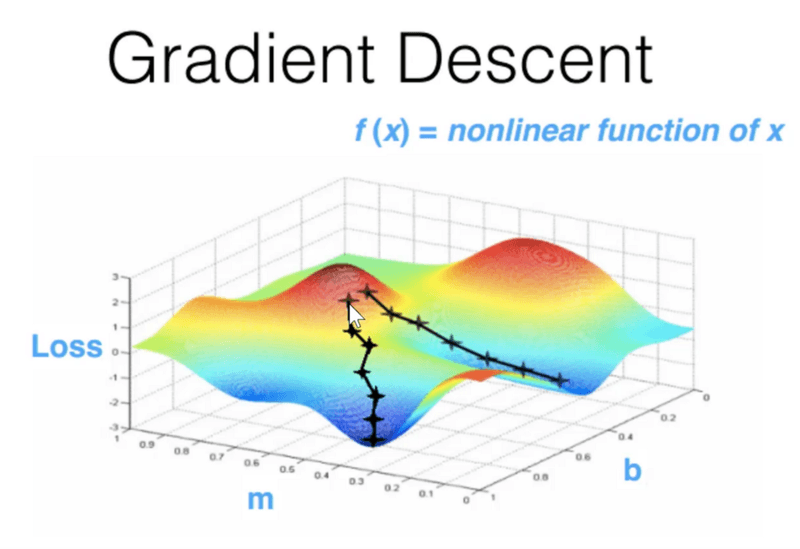
I also noticed that most of the scary words in machine learning were really just that: fancy words for concepts that anybody can understand! For example, do you know what stochastic gradient descent is?
It sounds super scary, but in reality it essentially means making an algorithm gradually suck less in an iterative way — i.e. making its suckiness gradually descend. The stochastic part just means doing that in semi-random strides instead of in perfectly accurate increments (because… it’s faster, that’s it). Just like a drunk guy gradually falling down a hill to where elevation is at its lowest.
The course itself was very well made, my main gripe with it being how inconsistent the quality of each chapter was (since they’re written by different people). I almost gave up a bunch of times during the worst written chapters. But the fact I could progress a little every day and that I had the interactive exercises to gamify my attention meant it was easy to gloss over the bad bits and constantly move on to the next chapter and get better. And more importantly, part of the course is teaching you to participate in your first friendly competition: estimating house prices.
Kaggle Competitions work like this: they give you a dataset, ask you to program an algorithm leveraging it, and you’re then scored and ranked on how good your algorithm does for the task at hand. Which means as I progressed through the course I slowly saw my housing estimator algorithm crawl up in the ranks which was incredibly motivating as it showed me I could do this.

The problem being, when I finished the course I was overwhelmed by a huge sense of “Ok but now what?” since I had no idea how to keep improving my algorithm beyond what I had learned. I tried to complete my knowledge a bit through the excellent Elements of AI theoretical course (which I recommend to do in parallel with a more practical course) but ultimately I felt stuck. So naturally, I completely panicked, dropped machine learning altogether for three months, and hated myself for ever thinking I could one day do this for a living.
But of course, while I dropped machine learning, the Internet did not. In fact I was reminded daily of how much I really really wanted to be able to do this. Every day it felt like a new breakthrough in the field or a cool new app using ML to do something I never thought possible before… like this kind of stuff:

Yes, I know some look like they long for the release of death, but still.
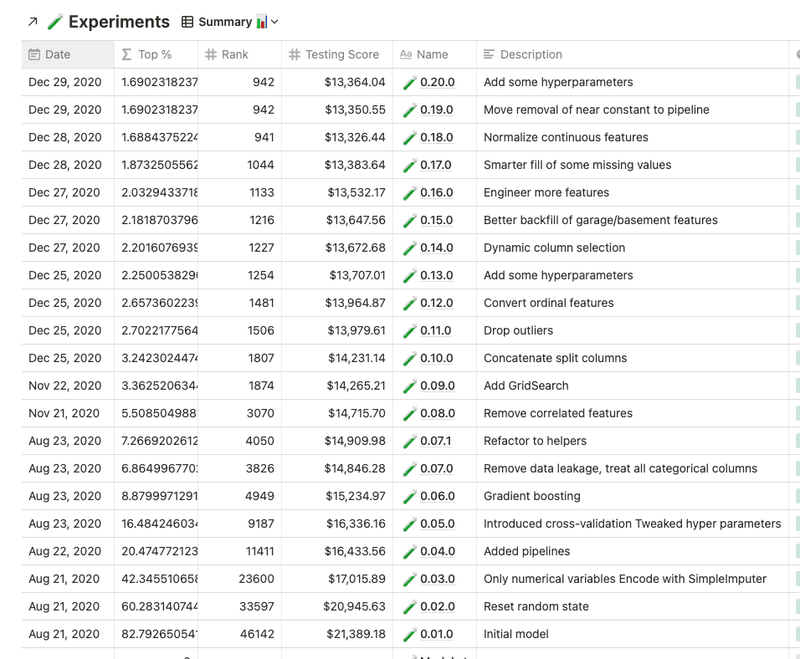
So I started looking at the leaderboard of the housing competition, trying to learn from them since the best part of Kaggle competitions is that entries are public and usually written in a very didactic manner. So you can just look at how the #1 person did it and learn from them.
And after a lot of learning, crying, and trial and error, I finally broke through the top 2% of the competition… which meant there were around 57,000 people who were worse at this than me! As weird of a way to frame it as this might seem, it was incredibly motivating and really filled my confidence meter again.
In addition to that I was allowed to use my newfound knowledge at work during audits and to experiment on ideas for Invox, which made the whole thing feel more concrete and helped cement myself mentally into my new capacities 💪.
The problem is that making a machine learning algorithm accurate is exponentially difficult, which means that going from top 2% to top 1% requires just as much if not more effort than to reach the top 2% in the first place. So I stopped trying to get higher in that competition and instead refocused my efforts on something closer to what I want to do in the end: neural networks and deep learning.
More precisely, what I want to do is work with Generative Adversarial Networks (GANs) which are neural nets specialised in generating new content similar to the content that they learned from (like GPT-3 does). Again, a super scary name for something that essentially boils down to: giving a generator neural net a lil’ buddy (the adversary in the name, or discriminator) and making the two of them ping-pong one another in a very fast feedback loop until what comes out is something both entirely new, but also still similar enough to the data the GAN was trained on.
A popular analogy I like is that of a counterfeiter trying to fool an expert, with each of them getting better over time as the counterfeit works get more realistic and the expert gets better at spotting fakes. When people joke about “I trained an AI on all the scripts from Seinfeld and made it write an episode,” that’s (usually) a GAN.
I already learned the fundamentals of neural nets during the Kaggle course, but they are an order of magnitude more complex than “classical” machine learning. And again, it’s really hard to see where to go from here as deep learning is its own entire field within the field of machine learning, and you can get lost just reading corpus summaries.
So I’m trying a different approach and trying to find more visual resources such as this short introduction series to help me wrap my mind around the concepts since I have a more visually-oriented memory. In one of those videos, they talk about digit recognition being the Hello World of neural nets, so since there is literally a Kaggle competition about this, I’m going to try to follow the same learning pattern that I did for classical machine learning and see where it takes me, hopefully to the top 2% again 🤞.

I’ll try to keep writing small progress updates like this to motivate me and to share what I learn gradually, but it can be hard to stay focused when every day it feels like a new research paper comes out, making my end goal seem further away. However, it’s also exciting because it’s AI and AI is bonkers future stuff! I really recommend the channel Two Minutes Paper which regularly explains new papers coming out and shows the progress in the field since the last paper on the subject. Some really mind blowing stuff in there!
See you next time for when I’ll be able to (hopefully) recognize badly written numbers 👋!









