






In the previous article, we explored generative AI and the substantial value that large language models (LLMs) can offer. As the field is rapidly evolving, there are a few key factors to consider when integrating AI solutions into your product. By the end of this article, you’ll clearly understand the available options and their unique characteristics.
AI options
Building your model using machine learning will require time, money, and manpower. It will also necessitate having an extensive amount of data on which to train a model. There are alternative approaches, such as integrating proprietary or off-the-shelf solutions. Due to the cost and time implications, a startup is more likely to choose this pathway. Doing so can unlock a world of opportunity, enable idea validation, and provide an entrance into the arena without a massive upfront investment. It can also reduce the time-to-market.
We divide these approaches into three tiers: proprietary models, open-source solutions and machine learning.
First tier: Proprietary LLMs
Several proprietary models can be explored: Open AI-ChatGPT, Claude, Titan, Grok and Gemini. Proprietary models offer a low barrier to entry, making it possible to integrate them into your application within just a few hours. Getting started is straightforward—simply create an account on the platform, link a credit card, and utilise the API. Since all models in this category are LLMs, the key skill required is prompt engineering. Prompt engineering allows you to create particular input prompts to work towards achieving the desired results without changing the model itself.
While the initial setup and implementation costs are minimal, the per-request fees can be significant. These models use a token-based cost structure, meaning that your costs will increase as your product scales and gains popularity. Moreover, if the LLM provider raises prices, your operational expenses will rise accordingly. This challenge extends beyond pricing. If the company behind the LLM updates to a new version, the model's behaviour may change, potentially affecting your application’s performance. Since you have limited control over the model—essentially treating it as a “black box”—prompting is the only tool available to engineers.
One example of proprietary LLMs is Open AI. Founded in 2015 and most famous for the models GPT-3 and GPT-4, Open AI had a vision of making AI open to all. Most famous for the models GPT-3 and GPT-4, Open AI moved to a capped profit model in 2019. While this enabled Open AI to move faster with its research, it also resulted in a move towards proprietary models. This was especially true for the more advanced models within its catalogue, such as GPT-4.
Integrating a proprietary LLM
When you use an off-the-shelf model, the primary focus should remain on the integration. This is your unique selling point. Be careful not to underestimate the need for further refinements. One of the tradeoffs for using an off-the-shelf model is that it will, in most cases, be generalised. Although it may have been trained on extensive amounts of data, the data may not be precise to the problem you are solving. Consequently, it will need some customisation. The options available here can be limited depending on your chosen provider, check what is available. As an example, ChatGPT only launched the ability to fine-tune in late 2023. Fine-tuning prompts is how we shape the LLM’s output, but this is also where limitations arise. You’re restricted to the capabilities of the LLM itself, and if tweaking prompts doesn’t yield the desired results, there’s little recourse for adjustment.
Despite these constraints, this tier is ideal for quickly validating ideas. If you have a promising concept that leverages AI, using a proprietary LLM allows for rapid implementation without a lengthy development cycle. Though you’ll incur higher per-request costs, this approach lets you gather feedback quickly. Once the feature is validated, you can transition to a more customisable and cost-effective solution from the next tier for long-term implementation. While LLMs excel at processing language-related tasks, they can also serve as a makeshift ETL(extract, transform, load) tool in certain cases.
Second tier: Open-source LLMs (Hugging Face / Llama)
The second tier we will explore is open-source LLMs. Although some of these still have corporate ties, such as Llama, which remains overseen by Meta, this tier offers more transparency and flexibility.
Hugging Face is an example platform containing many of these models. Founded in 2016 Hugging Face was initially focused on chatbots. It later became more widely known for its open-source transformers library, which was launched in 2019 and provided access to advanced pre-trained models, including Open AI and BERT. Today Hugging Face has over 100,000 models. Another example platform you could explore is TensorFlow Hub.
Compared to the first tier, the main differences between open source and proprietary are that open source has a big community, allows for greater customisation and provides access to a wider variety of models. However, the tradeoff is that you need more experienced team members to work with the models.
Where proprietary models mainly rely on prompt engineering, open-source LLMs have more approaches to customise a model for your solution. Fine-tuning and adapter-based tuning are examples of these. When you fine-tune a model, you retrain the model on a data set specific to your solution. Adapter-based tuning is a form of fine-tuning foreseen by several open-source models. It allows you to add small layers to an existing model. The layers themselves are trainable; you make minimal adjustments to the task, but the pre-trained parameters remain the same. This approach is optimal for businesses with specialised requirements demanding a high degree of customisation. It involves more effort but brings long-term benefits and greater control over the system.
Compared to proprietary platforms, open-source models give you more options over hosting. For example, with Hugging Face, hosting the model on the platform itself can be the easiest deployment option. This can combine straightforward model serving and API integration. Depending on your requirements, the downside of this means that while this simplifies deployment, your application becomes more tightly coupled to the Hugging Face infrastructure. This can limit flexibility in the same way that proprietary models are hosted in their ecosystems. The effort which would need to be invested to move to a different infrastructure should be considerd. Additionally, hosting on Hugging Face may incur costs based on usage, which should be factored into long-term planning.
To mitigate these constraints, you can self-host open-source models on major cloud platforms like Azure, AWS, or Google Cloud. This approach offers more control and potential long-term cost savings, but requires deeper technical expertise in MLOps and infrastructure management, along with higher initial setup costs. A hybrid approach using multiple models across different platforms can balance these tradeoffs while maintaining deployment flexibility.
Third tier: Building your own model (machine learning)
The third tier is outside the scope of this article. It would entail using machine learning to build your model and train it on large amounts of data. Fine-tuning could be used to enhance the model's performance. Taking this approach would mean creating LLMs that can perform very well on specific tasks but potentially at a significant cost, both in terms of computational power and financial resources, particularly for large models.
Comparing Open AI and Hugging Face
The pricing for the OpenAI API is based on usage, making it flexible but potentially expensive for high-volume tasks. As the API usage scales, so do the costs. prices.
Here is a similar comparison of the main models on Hugging Face:
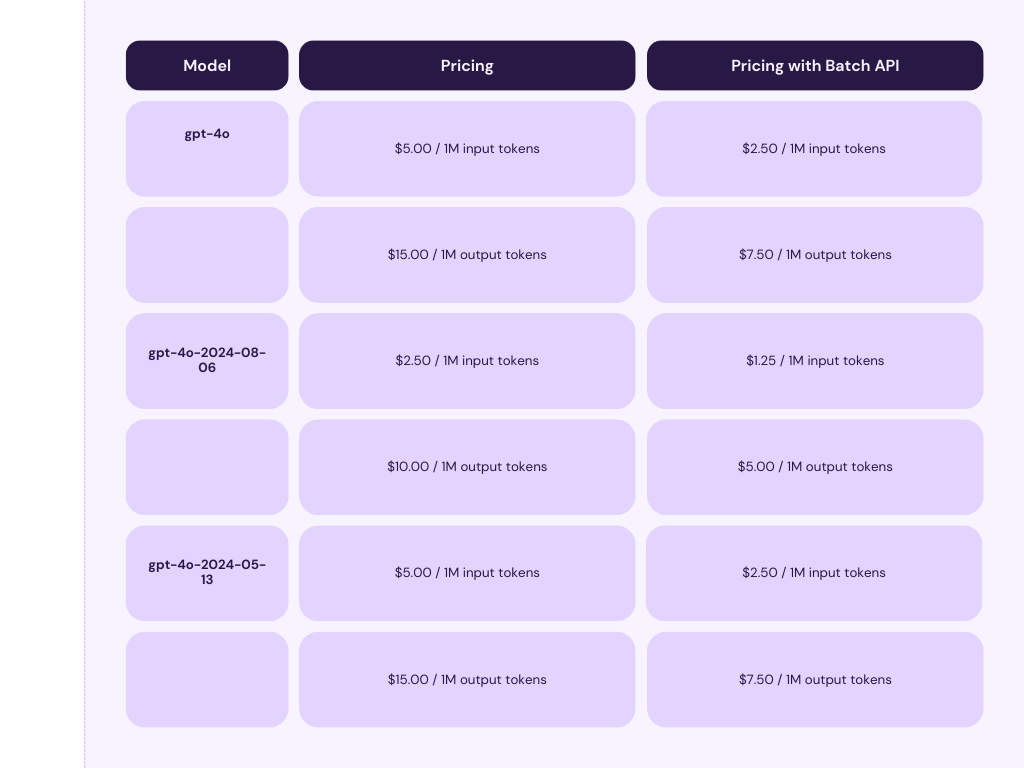
Here is a similar comparison of the main models on Hugging Face:
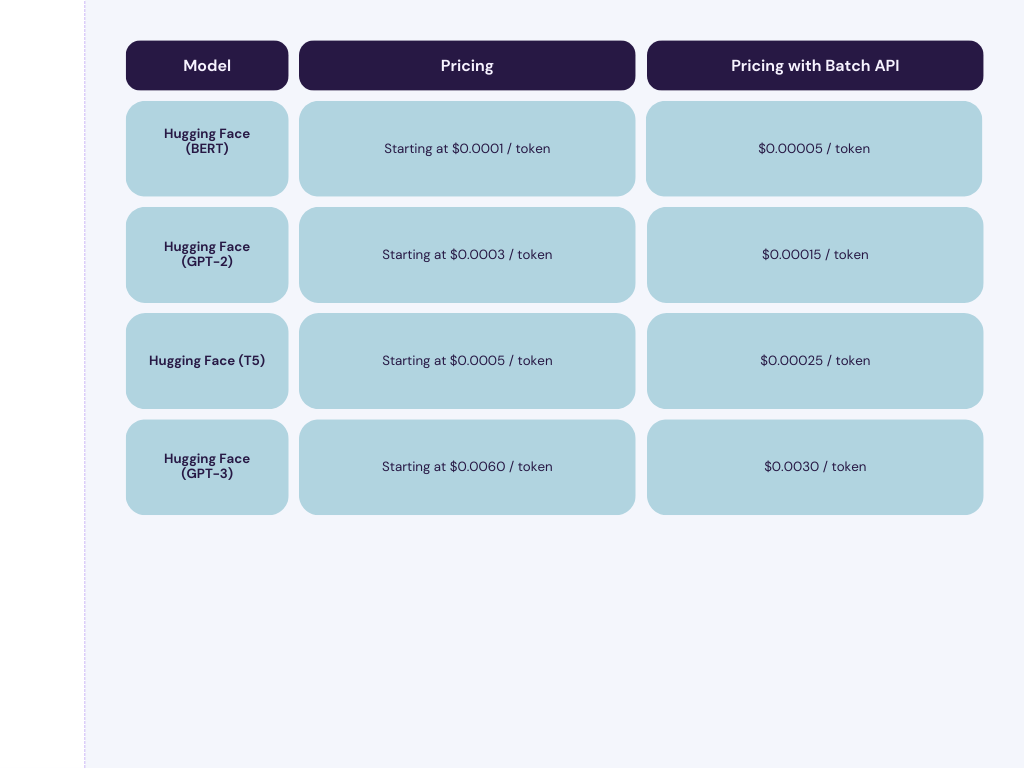
Both platforms provide monitoring tooling so you can continually review performance. Let's look at a summary of the pros and cons of Hugging Face vs. Open AI.
Hugging Face
Pros:
- Open source: The models are open source, and the platform is driven by a community.
- No fees: Due to the fact the models are open source, there are no licensing fees.
- Customisation: The models are highly customisable.
- Choice: There are many models to choose from to solve various problems.
- UI: The website is user-friendly
- Tools: The website has many tools, and it is linked with AWS SageMaker. Accelerate and the Inference API also help with scaling. Accelerate enables PyTorch code to run across any distributed config. Inference is a cloud-based service for running models in production without managing infrastructure.
- Ethos: They are democratising AI
- Community: Active community support and updates
Cons:
- Knowledge: The models may require more profound knowledge. Their greater flexibility requires more knowledge to maximize it, creating a steeper learning curve.
- Costs: The costs for maintenance and infrastructure
- Time: The time required to initially get everything set up
- Resources: Computational resources for customising a model
- Additional costs: Enterprise features such as dedicated support will cost more.
- Inconsistency: Some documentation may not be as maintained as others.
- Maintenance & Hosting: You will need to maintain and self-host the model.
OpenAI
Pros:
- Accessibility: Access to cutting-edge and robust models.
- Ease of use: Simplified integration
- Performance: This is a known entity, and from the start will be good.
- Stability: They are supported by Microsoft, which means they are stable. The addition of Azure to the infrastructure provides security benefits.
- Deployment: A shortened deployment time
- Updates: The models receive frequent updates.
- Documentation: The documentation is detailed and includes examples of usage.
Cons:
- Cost: Expensive
- Customisation limitations: The models are limited in how you can customise them.
- Lock-in: Licensing and vendor lock-in and proprietary
Deciding what tier to use
When integrating an off-the-shelf model, you should start by defining the problem you are trying to solve. Be specific about what you want to gain from using the LLM, and choose the metrics you will use to measure the solution. When you are clear on all of this, you will be in an excellent position to explore the available models.
Once you explore the models, decide whether you wish to use proprietary or open-source models. This will help you decide which provider to go with. You will also want to consider your financial and performance limitations. Undertaking a phase of experimentation will help you gain a deeper understanding of both how the model works and how the pricing structure will work for you.
One of the common concerns when using an off-the-shelf model is how it can be scaled. It is essential to avoid getting too caught up with the concerns until you have the customers for this to be a problem. When you reach this problem, much can be done, starting with defining where you are starting to become limited. Cost or the time involved in processing data are two examples of issues which may arise. Techniques are available to optimise the model, and you can also reconsider performance optimisations, such as caching, alongside how it is distributed and hosted.
Focus first on building the customer base. Whilst you will not have the IP of using a bespoke model, many options are still available to gain a competitive edge. Explore areas such as customising the model, integrating it into specific niches or combining models to solve a new problem. Explore the pain points of other integrations and see where you can go beyond the model's functionality. The core feature of all or most of these focuses on how you can integrate the model. UI and UX can be standout factors here. Can you combine a beautiful front end with a model that solves a complex problem or a tedious one?
Conclusion
Using an off-the-shelf model can reduce overhead, helping you integrate AI into your product or operations. Consequently, this is an excellent option for undertaking proof of concept work or building an MVP.
Carefully consider how you can differ from competitors and what the most impactful ways are from a user perspective when you integrate the model. It cannot be understated that this is the area where you will shine when you take this approach.
Overall, OpenAI will help with rapid, lower-effort deployment, which is ideal when time-to-market is critical. On the other hand, Hugging Face will provide you with greater flexibility. Open-source models, in general, may give you greater freedom, and it is less likely you will be presented with sudden changes. You may opt for Open AI in the early stages, but when you wish to create something more competitive, or you require greater flexibility, a move to Hugging Face may be more appropriate. Understanding the trade-offs will help you select the most ideal AI implementation method for your business, ensuring you can effectively meet technical and business objectives.





Member discussion