

Creating branches in git is blazingly fast and having a bunch of them is pretty cheap. This means we get to merge them quite often. But how is a branch represented internally and what does it mean to merge them? Understanding how this works internally will help you understand why merge conflicts occur. Let’s dispel the magic.
Branches as pointers
If we visualize git’s commit history, each commit is represented as a node on a graph. Each commit has a connection to its parent; we can only travel from a commit to its parent(s) when traversing the graph:
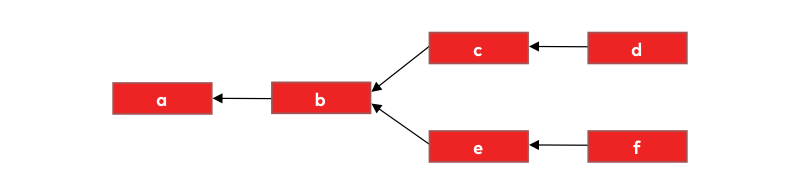
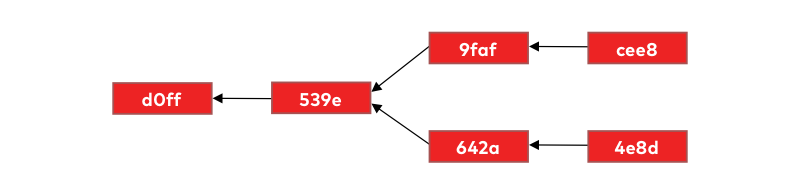
We know in reality git uses those random-looking strings as commit identifiers (checksum headers) so let’s use them too:
It’s very intuitive to think of a branch as a list of commits, but a branch in git is just a pointer (reference) to a commit:
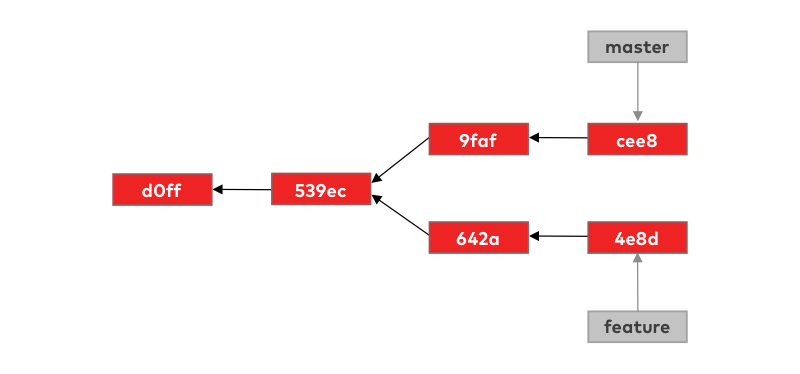
The commit that the branch references is the last commit on that branch, so we also call it the tip of the branch.
We know that when we use git log command, git shows a list of all commits on the branch, not just a single commit, so how does this work?

Well, if and when git needs the full list of commits that a branch contains (in this example master), it will generate it by traversing the commit-graph starting from the tip of the branch:
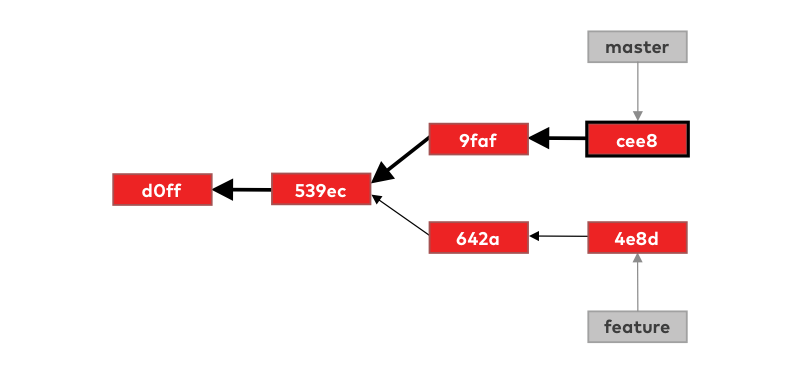
You can still think of branches as lists of commits, but git doesn’t need to keep this full list stored somewhere all the time. It only needs to keep track of the tips of the branches and simply generate the full list when it’s needed
Everything is in the commit
We can think of commits as points in time in the history of our project. Every one of these points represents the changes made to the project at that point. In git, every commit also includes the full state of your project at the point of the commit.
This means when you checkout to a specific branch git doesn’t need to traverse its full list of commits (applying changes from each commit) to recreate the state of your project (to match that branch). It only needs to look at the tip of the branch.
The reality is a bit more complex but you can think of it as every commit containing a list of all the files in your project with the version identifier of the file. In this simple example we have only three files in our project and have committed the initial version of them in our first commit:

If we change the kernel.php file and commit those changes, the next commit will still contain the same list of files, but the version identifier for kernel.php will be updated.

Git uses these version identifiers to quickly search its data storage for the object containing the content of that exact version of the file. Different version identifiers for the same file mean the content of the file has changed.
Now that we know how git branches are represented at a low-level, let’s see what it means to merge them.
Merge
Going back to our example, suppose our shiny new feature is done and we want to merge it to the master branch. In other words, we want the changes we did on the feature branch to be present on the master branch as well.
If we traverse the commit-graph starting from the tip of the master branch, we can see that those two commits from the feature branch are not accessible from that tip. This, in turn, means the changes we did on those commits are also not present on the master branch.
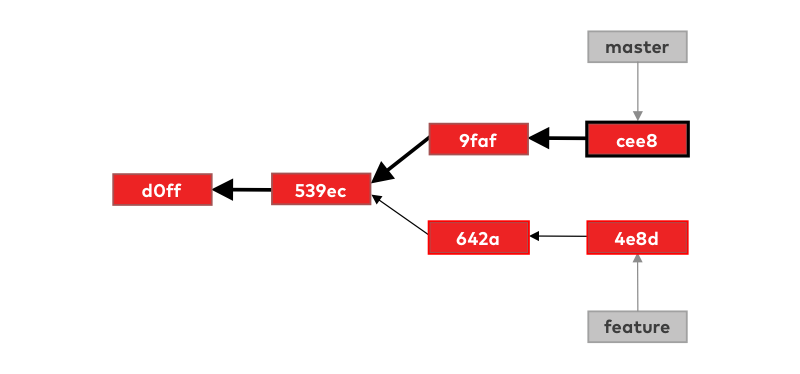
The result we want to achieve by the merge is to make those commits accessible from the tip of the master branch.
The first step in the merge is to find the merge base commit. This is the commit after which our branches diverged. Git finds it by going to the tips of both feature and master branches and traversing the commit-graph until it finds the first commit that is accessible from the tips of both branches:
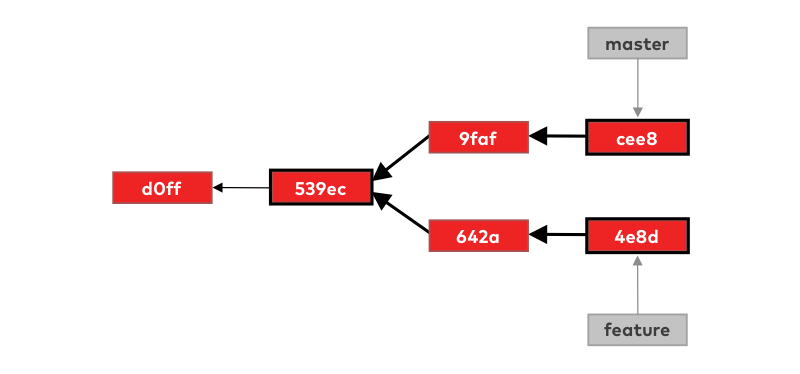
Once it has located the merge base, git will start building the new merge commit. This merge commit, once it’s done, will have an interesting property — it will have two parents.
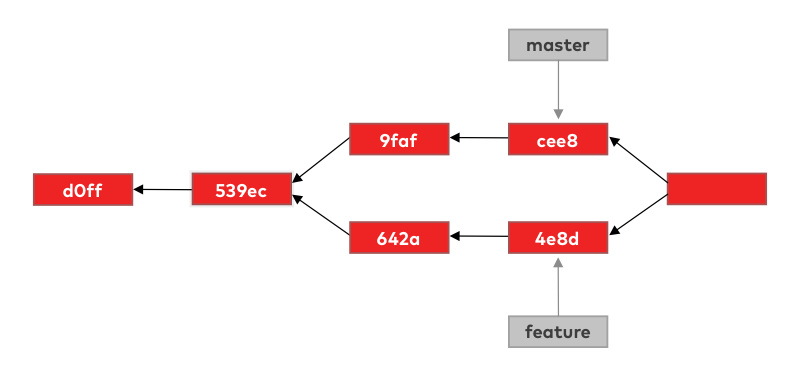
The first parent will be the current tip of the master branch and the second the current tip of the feature branch. Because of this property, the new merge commit will have access to all the commits from the master branch but also to those two new feature branch commits as well.
To construct that new merge commit git needs to decide what versions of our files go into it. To do so, git will compare information from the merge base and the tips of master and feature branches:
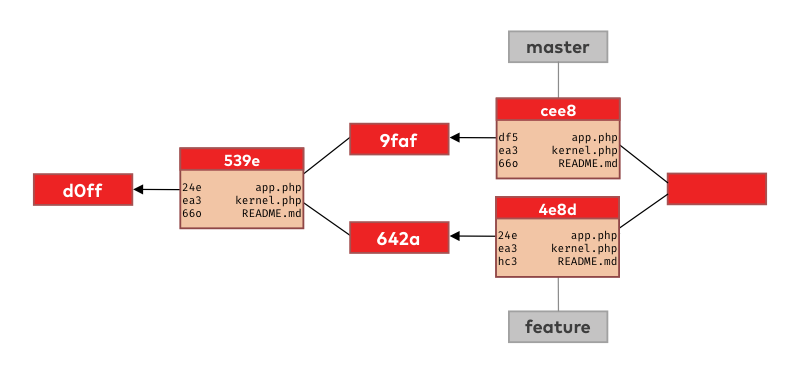
The first file in the commit’s list is app.php. Git compares the file version identifiers in the merge base commit (539e) with the ones in the tips of master and feature. The version identifier on the master branch (df5) is different than in the merge base (24e) while the tip of the feature branch has the same identifier (24e) as the merge base. This means we have only changed the app.php on the master branch so this is the version git will put in the new merge commit.
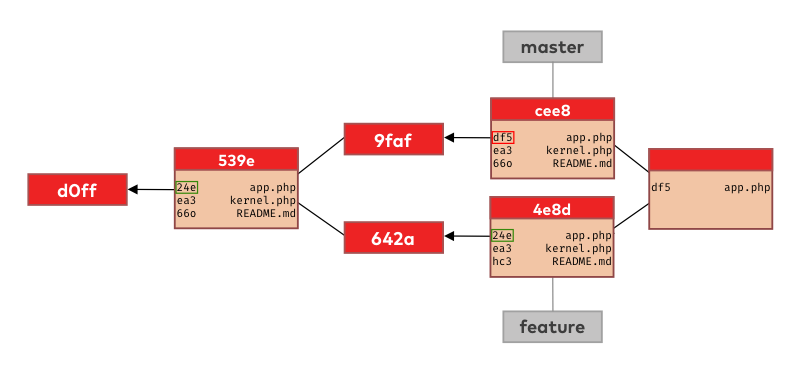
The next file in the list is kernel.php. The situation is a bit simpler now since we didn’t change this file on either of our branches. Git knows this because the version identifier is the same in all 3 places (ea3) so git will take the version from the base commit and put it into the merge commit.
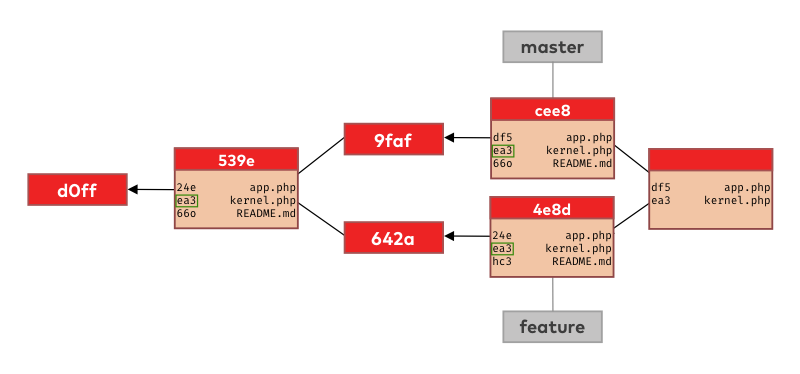
Finally, when looking at the last file on the list (README.md), git sees we changed it on the feature branch only so it’s again smart enough to realize that it can take that version (changes) and put it into the new merge commit.
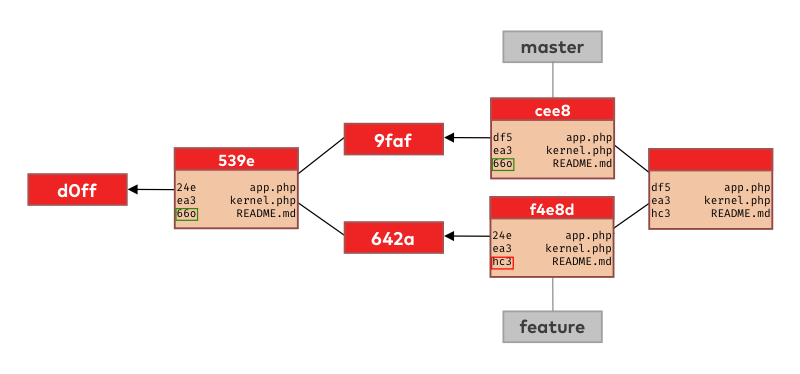
Once the merge commit is constructed the only step left is to update the master branch pointer to point to the new merge commit, which is now the new tip of the master branch.
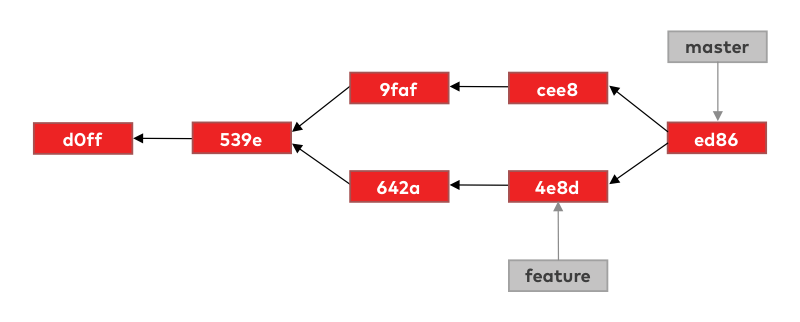
From this new tip, those commits made on the feature branch are now accessible so the changes we did on those commits are also present on the master branch.
What about conflicts?
Git can be smart enough to do the merge automatically as long as we didn’t change the same file on both branches. If that is the case, we have a conflict and git needs our help.
Consider the scenario from before with a minor difference. This time when git is trying to construct the new merge commit it finds we have changed the README.md file on both of our branches.
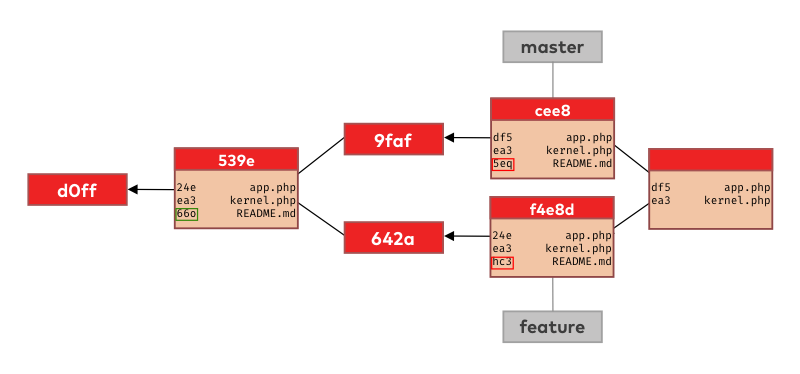
Git cannot read our minds and know which of these file versions (changes) is more important to us, so it will stop the automatic merge process and ask for help.

The message git gives us is to fix the conflict in the README.md file and then manually create the merge commit by using the commit command. So, let’s fix that conflict.
If you open the README.md file you will see git has added textual markers to it to indicate the conflict.
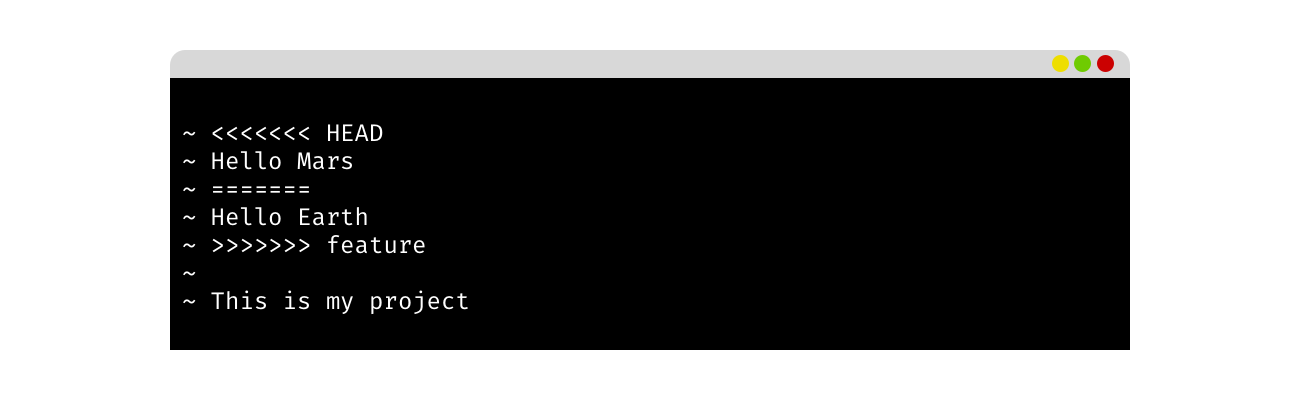
The content between the <<<<<<< HEAD and ======= is how this line of the README.md file looks on the master branch while the content between the ======= and >>>>>>> feature is how it looks on the feature branch. To resolve the conflict you simply need to make the file look as you want it. In this case, we want the Hello Mars text so we would delete the markers and the Hello Earth line:

Now we need to type git add README.md to let git know we have resolved the conflict and git commit to actually make the new merge commit. Git will give it the automatic Merge branch 'feature' commit message but you can also change it to whatever you want.
People usually use a GUI tool, such as SourceTree or the one built in to your IDE, to resolve conflicts because manually inspecting the files and making sense of those textual markers git gives can become cumbersome.
Fast Forward
Because branches in git are just pointers to commits, merging can become quite a trivial operation at times. Consider this example:
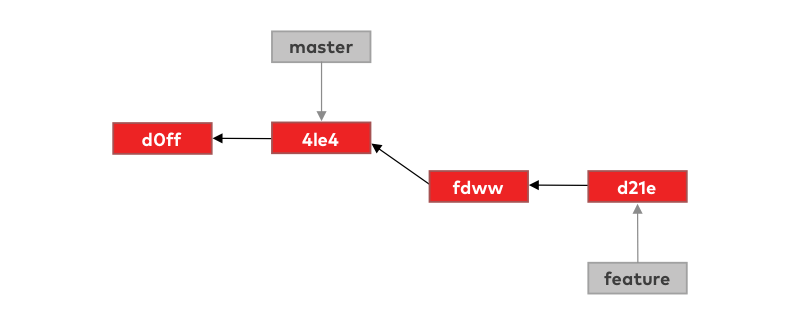
We have created a feature branch and made some commits on it, but in the meanwhile, we didn’t do any changes (commits) on the master branch. We can say that the tip of the feature branch is ahead of the tip of the master branch (by two commits). This becomes even more clear if we slightly modify our visualization:
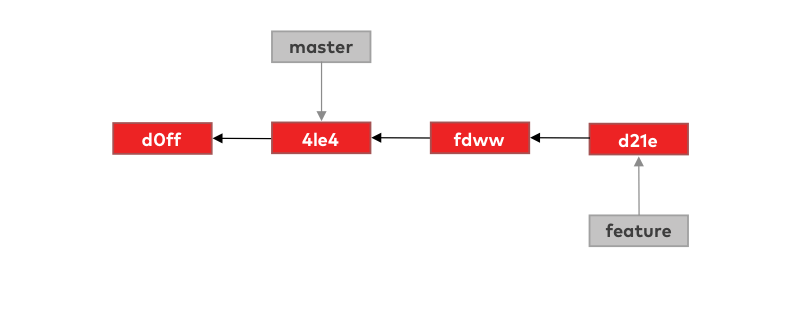
As we showed, to merge the feature branch into master means to make those two commits from the feature branch accessible from the tip of the master branch. To do so git can simply move the tip of the master branch forward:

The only caveat here is that git will not create that special merge commit, so by looking at the history log of the feature branch, you won’t be able to tell it was merged with the feature branch at some point. If you do need this information, you can pass the --no-ff flag to the merge command and it will always create the merge commit.
To answer our questions from the beginning, branches in git are just pointers to commits (tips) and merging branches is all about making commits accessible from the tips of branches. I hope with this understanding of the way that git works you see through the magic. Now you will be better suited to tackle any problems you have with branching. So merge often, have fewer conflicts, and live long and prosper!









