




“Can we add all the birds in the galaxy?” That sentence alone should have been a red flag.
All the birds. Every single one. Not just their data but the photos, the sounds and the icons too.
At the time, Mossie was a birding app born out of an internal learning project at madewithlove, with about 300 species entered manually by a group of very enthusiastic birders. I joined that project as a complete birding noob. While others casually threw around Latin names and obscure sightings, I was still figuring out whether we were talking about animals or rejected Harry Potter spells.
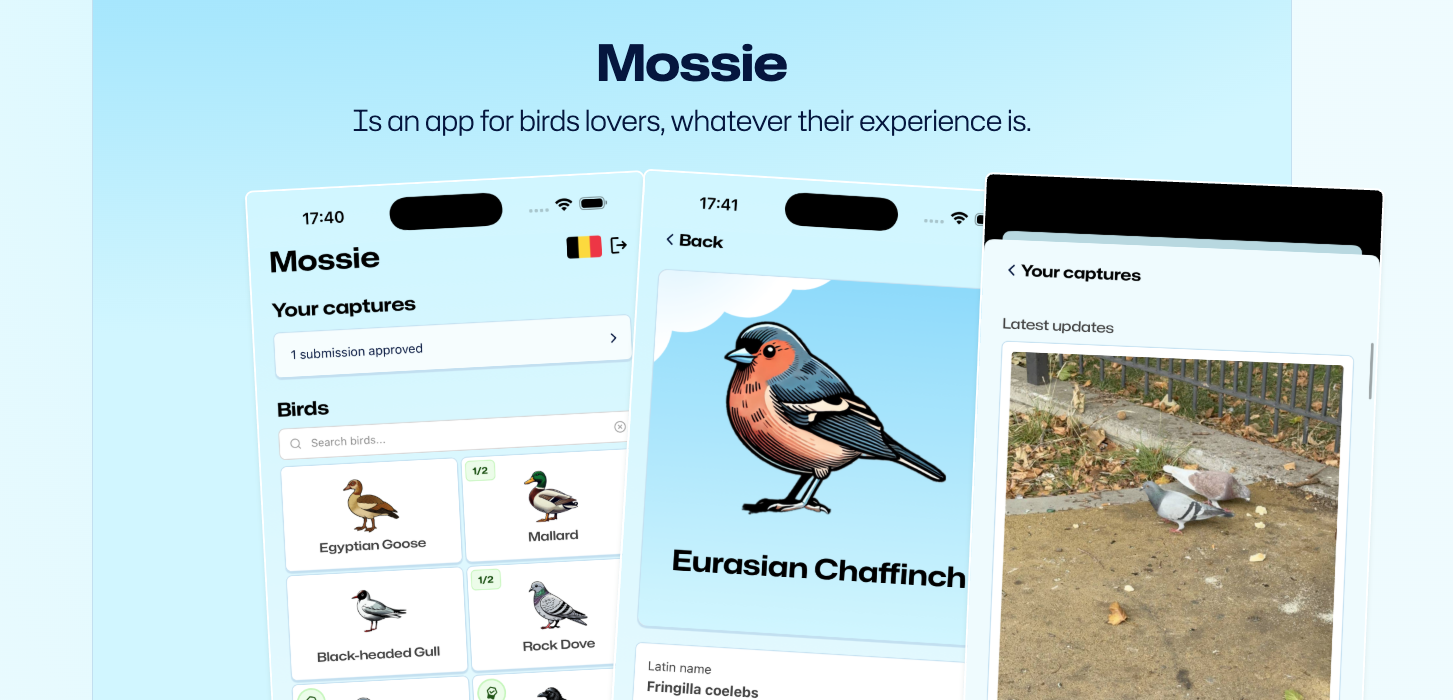
Mossie is a playful bird-spotting app we've built that helps people learn to recognise birds by observing, comparing, and recording sightings while exploring nature.
It felt like stepping into Star Wars. Everyone spoke a foreign language. Everyone knew the lore. I was just trying to identify who was human and who was a Wookiee.
I didn’t bring a lightsaber. I brought a serverless GenAI stack.
And instead of stormtroopers, I fought ETL retries.
The impossible ask
“All the birds” turned out to mean 11,089 living species.
Not just their names, but:
- Pictures
- Sounds
- Metadata (translated names, weight, size, wingspan, category)
- Location data
- And cute, consistent icons
Scraped, enriched, validated, hallucinated just enough to be useful, and pushed through a pipeline without burning down our infrastructure or our budget.
After that, things got weird: broken taxonomies, missing data, hallucinated measurements, and an OpenAI invoice that briefly triggered a Death Star–level response from management.
Reality check: Taxonomy is chaos
Here’s something no one tells you: biology is a pseudoscience, at least when you try to turn 300 years of academic debate into a clean JSON schema.
Species names change. They split. They merge. They reappear years later under a different name, like Palpatine in The Rise of Skywalker. Even Latin names, supposedly the bedrock of taxonomy, aren’t consistent across sources or versions.
One dataset says Columba livia.
Another adds a subspecies.
A third quietly moved it somewhere else because the birds interbred until nobody was quite sure anymore.
And that’s the best case, assuming the data exists at all.
Because the next discovery was more unsettling: some birds simply do not exist on the internet. They show up in global taxonomies with:
- No Wikipedia page
- No picture
- No sound recording
- No description beyond “small” and “found somewhere forestry”
Imagine querying the entire internet about a bird and getting a collective shrug:
“idk bro, kinda brown?”
At that point you don’t have a data pipeline, you have a digital séance.
But the bird floodgates were open. We had committed. So we did the only reasonable thing.
We built the pipeline.
A clone factory of birds
Turning “all the birds” into something real meant building more than a script. We needed a fully serverless, parallel, semi-intelligent ETL pipeline that could scale to thousands of species without collapsing under its own assumptions.
Naturally, we built it in Python, packaged it in Docker, and deployed it on AWS Lambda orchestrated by AWS Step Functions. Each bird became an independent unit of work flowing through the same state machine: enrich, validate, generate assets, persist. Parallelism everywhere. Retries where they made sense. Observability as a non-negotiable.
At a high level, every species ran through its own isolated workflow. A failure to fetch images for one obscure forest dweller wouldn’t block thousands of perfectly well-documented birds behind it. This architecture let us push concurrency hard while keeping the blast radius small, which became critical once “edge case” started to mean “hundreds of birds.”
This wasn’t a script, but a clone factory.
Step 1: A proper bird data lake
We started from a single input file of one taxonomy: BOW 15.1, the Birds of the World list. Each bird’s Latin name is our primary identifier, with translated names bundled in.
From there, we built a real data lake in S3:
- One JSON file per bird
- Directory structure by first letter of the Latin name
- Designed explicitly for parallel processing
An encyclopedia. Except this one might actually be complete.
Step 2: The taxonomic nightmare
Next, we enriched the data using an Excel file with metadata like diet and weight.
Of course, it was based on a different taxonomy, used different Latin names, and was only partially filled in.
When names matched: great. When they didn’t: we did the only sensible thing.
We threw it at GPT-4o and whispered:“Help me, Obi-GPT Kenobi, you’re my only hope.”
GPT acted as a taxonomic droid, matching synonyms and alternate names and merging the data surprisingly well.
Lesson learned: GenAI excels at fuzzy joins across messy, human-defined domains like biology, but only when it’s treated as a probabilistic matcher rather than a source of truth.
Step 3: Core metadata (and mild despair)
Mossie needs basic stats:
- Category (seabird, raptor, etc.)
- Weight range
- Size range
- Wingspan
This is where things got uncomfortable.
LLMs are not trained on every bird. Some species simply don’t have public measurements. Wingspan data, in particular, is rare.
So when the archives failed us, we embraced the dark arts:
wingspan = K * √weight
Where K is a secret constant per bird category, calibrated entirely on vibes (and midichlorians).
All tests passed.
At this point, I stopped questioning science.I just accepted the vibes.
Step 4: Image search, AKA bird roulette
For images, we used Google Custom Search.
Sometimes we get majestic, high-res nature photography.Other times?Stock photos of chicken nuggets, corporate logos, or a guy named “Rifleman.” Well, it’s to be expected, given the bird's name, “Rifleman”.

Step 5: Borrowed bird sounds
For audio, we scraped a large community archive of bird calls.
We kept references to original uploaders, because behind every beautiful recording is a birder standing motionless in a forest, holding a microphone, quietly questioning their life choices.
Step 6: Icon generation
Finally, generating Mossie’s iconic bird icons.
We used gpt-image-1, fed it reference photos, and asked — politely — for:
“Draw this bird like 1 of your French girls in Mossie style. Cute. Minimal. No background. Please… no hats.”
At scale, it worked. Thousands of icons in minutes.
Occasionally… it didn’t. Apparently, LLMs don’t only dislike fingers.


Mossie is a playful bird-spotting app we've built that helps people learn to recognise birds by observing, comparing, and recording sightings while exploring nature.
To be continued... Part 2 will be about scaling the app and the costs! Subscribe to stay in the loop.




Member discussion