




Scale breaks everything
At a small scale, the pipeline was elegant. Real Order. At a large scale? More like Order 66.
A 99% success rate sounds great until you run it 11,089 times. That’s over a hundred edge cases per step.
Some highlights included filenames longer than Unix limits, Wikipedia gaps, image searches returning PDFs, 404s, or suspicious `.exe` files, and models inventing categories that turned out to be correct because we’d missed them.
Scale doesn’t punish clever ideas. It punishes assumptions.








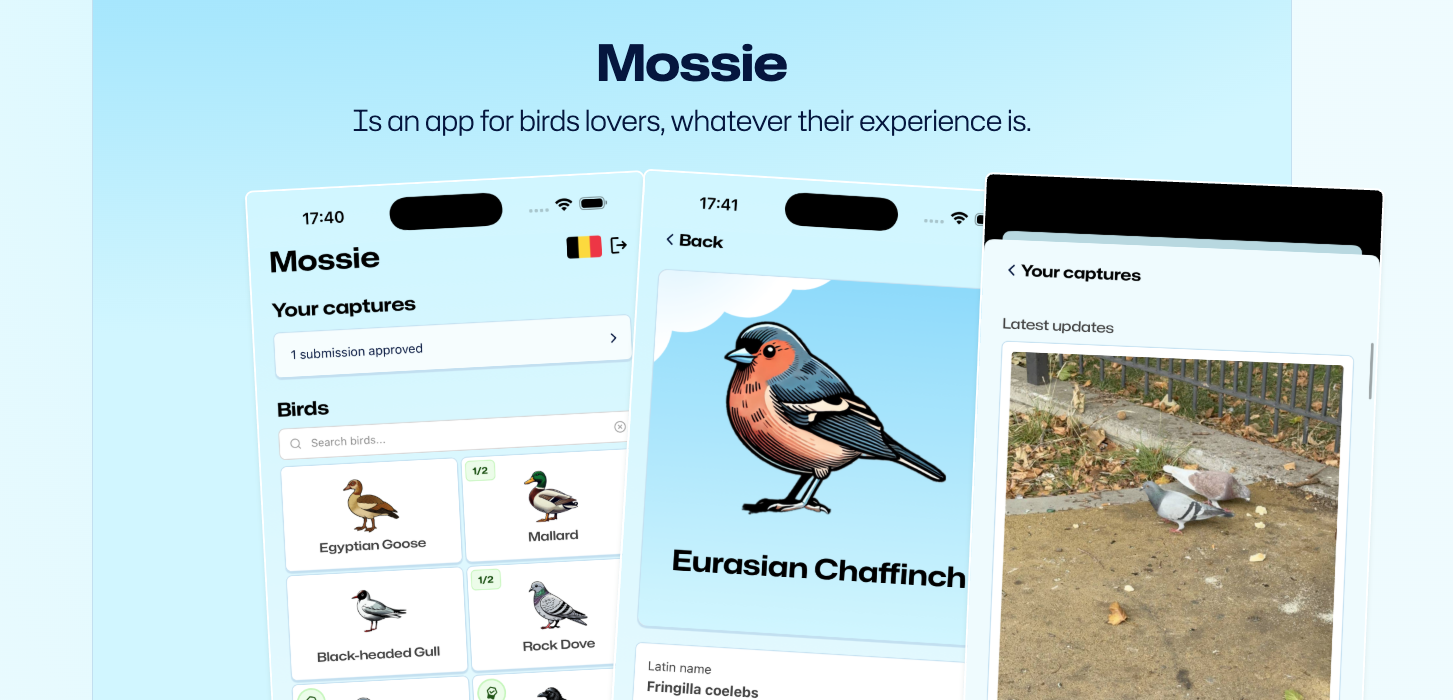
Mossie is a playful bird-spotting app we've built that helps people learn to recognise birds by observing, comparing, and recording sightings while exploring nature.
Geography is also chaos
Having all birds introduced a new problem: relevance. Most users don’t care about birds living half a planet away.
So we scraped millions of occurrence records — real sightings mapped to locations. Scraping was easy. Mapping locations was not.
Geography, it turns out, is also a pseudoscience.
We spent absurd amounts of time translating and normalising place names. “Niederösterreich” became “Lower Austria”. “Al Fujayrah” quietly lost its prefix. “Liverpool” stopped being a city and turned into “Merseyside”.
Birds don’t read maps. They migrate, wander, and occasionally show up in Finland because one got confused in 1987. This is where static databases break down. A bird “exists” in taxonomy, but relevance is probabilistic, temporal, and geographic.
Mossie needs both sides of the picture: the theoretical habitats birds are supposed to occupy, and the locations where they actually show up. That tension matters.
When the bill strikes back
Then came the load test. Run on a Friday. End of day. Naturally.
While I was fixing bugs on a customer project, OpenAI emails started arriving: “Your API account has been funded.”
Plural.
Management responded by nuking my API keys. The damage: ~$140 for less than 1,000 birds.
Two villains emerged. Always two there are, no more no less.
- Web search was expensive, noisy, and allergic to clean JSON.
- Image generation turned out to be far costlier at scale than expected.
Retries were killing us. Image output tokens were burning the budget.
The future of the Mossie data pipeline was looking b(l)eak.
Rebuilding with budget in mind
Armed with old-fashioned spreadsheets, token counters, and the uncomfortable clarity that this was no longer a thought experiment, I had to rebuild the data pipeline and create a proper estimate.
The first issue was obvious in hindsight: the pipeline had been restarted multiple times due to errors at scale. Many ETLs ran far more often than necessary. We fixed this by adding an early stop to each step when the current version of the data lake already contained the expected output.
Next was web search. The model was still in preview, and no amount of prompt tweaking reliably produced the desired JSON. Retrying the entire pipeline step every time a response went sideways was expensive due to the web search cost itself, so we pushed retries down into code instead. We reused the original search context and handed it off to a regular, much cheaper GPT-4o prompt whose sole job was to turn that search result into structured JSON. As a Windows machine would say, the task failed successfully.
Finally, we tackled image generation. The biggest cost driver was output tokens. There was a quality toggle with three options: low, medium, and high. The default, unsurprisingly, held the high ground.



The average cost per icon per quality option is:
- Low: $0.017
- Medium: $0.047
- High: $0.177
That looks quite ok. But we need to look at this for our scale (being times 11089).
- Low: $188
- Medium: $521
- High: $1963
High quality was never going to fly for a side project. Medium wasn’t great either — it lost detail and the vectorised look we wanted. The breakthrough came when we revisited the prompt: certain wording caused the medium-quality model to degrade in ways the high-quality model masked. Changing settings meant changing prompts too.
With retries fixed and image costs under control, we could finally build a trustworthy estimate. The math said we still needed $900 — and this time, we could go back to management with a straight face.
What we ended up with
The pipeline was set up to process per starting letter, 40 birds parallelised at a time with an average speed of 37 birds per minute. Once the smoke of the hard-working GPUs cleared, this is what remained:
- 11089 enriched birds with translated data and metadata (Weight, length, wingspan, category)
- 82GB of annotated Wikipedia images
- 124h of annotated bird sounds
- $520 worth of AI-generated stylish icons
- 20 million bird locations
- ~$960 total cost
What this unlocks
This dataset is just the foundation. The future of Mossie isn’t static bird lists. It’s living maps:
- Real-time sightings
- Shifting migration patterns
- Hotspots that change while people are birding
The real challenge ahead is balancing accuracy, freshness, and scale across multiple sources in near real time.
So, join the flock. Bring your binoculars. The next chapter of Mossie isn’t just about birds; it’s about building the map of a living, breathing galaxy of sightings in real time.
May the birds be with you.
Mossie is a playful bird-spotting app we've built that helps people learn to recognise birds by observing, comparing, and recording sightings while exploring nature.
If you’re curious, Mossie is available on Android and iPhone.





Member discussion