


“Wait, what? Cloud Run is serverless!” I hear you shout in confusion as you jump out of your chair. Well, give me a chance to explain because, apparently, this is not something that has been tried before. At least it’s not well documented online, as I am sure your searches have come up dry — until now!
Cloud Run is Google’s serverless container platform, where you only pay for request processing time. This is how most folks know Cloud Run. However, few seem to realize there’s a setting that turns Cloud Run on its head: always-on CPU. In fact, it’s not that new; the availability of that setting was announced on September 14, 2021.
If you are working on a reasonably sized web application, you will sooner or later arrive at a point where a background job queue worker becomes necessary. You could use Pub/Sub instead, but it will only take you so far.
We once joined a project running in Google Cloud Run where the team decided to leverage what was already there, infrastructure-wise, for job processing, namely Pub/Sub. However, it quickly turned out we were bending over backwards and abusing Pub/Sub for background processing.
The team needed a proper background queue worker. Continuing to use Pub/Sub for our needs wouldn’t scale. Furthermore, the 600-second request limit in Cloud Run would no longer satisfy the necessary requirements.
As I dove into this subject, I really wanted to have a Laravel Horizon queue worker set up, as it is so well integrated with Laravel, the framework used on the aforementioned project.
Additionally, we had to break out of the HTTP request context altogether, especially for long-running jobs. However, I always do my research first before making a final decision.
I explored the possibility of using Google Cloud Tasks (check out this package). That technology works by making an HTTP request with the job payload to your application, something we wanted to avoid. So this was a no-go.
There’s also Batch API, but that one effectively means starting a container with custom arguments — light years away from the simplicity of dispatching a job in Laravel.
We also considered using Google Compute Engine. However, the whole project uses Cloud Run. If we have a “server” to maintain, it would mean we’d have to heavily customize our deployment pipelines and keep it up-to-date.
I finally decided to have a closer look at Cloud Run and determine how it possibly can be used in a non-serverless fashion for hosting Laravel Horizon. As it turns out, the always-on CPU feature of Cloud Run was exactly what we needed. You can find it after clicking the “Edit & deploy new revision” under the “Container” tab:
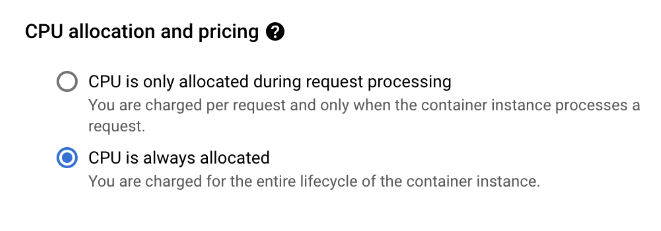
There’s more to the story, though. I spent some time pondering on how we can use the same production container image so maintaining this queue worker doesn’t make our life harder.
Under the aforementioned “Container” tab, you’ll find a “Container command” field. We use an Apache image, but… I decided to install Supervisor as well so that we could start it here by passing a command:

For reference, these are the files that end up at /etc/supervisor/conf.d/:
# supervisord.conf
[supervisord]
nodaemon=true
# horizon.conf
[program:horizon]
process_name=%(program_name)s
command=php /var/www/artisan horizon
autostart=true
autorestart=true
user=www-data
redirect_stderr=true
stopwaitsecs=3600But wait, there’s more! If you deploy your container like that, Cloud Run will consider the service unhealthy because it doesn’t respond to the health check request.
Because we are using an Apache image, we can easily fix this. Maybe it’s a bit overkill, but all we have to do is use Supervisor to also start Apache:
# apache2.conf
[program:apache2]
process_name=%(program_name)s
command=/bin/bash -c "source /etc/apache2/envvars && exec /usr/sbin/apache2 -DFOREGROUND"
autostart=true
autorestart=true
user=www-data
redirect_stderr=true
stopwaitsecs=3600
p.s. Don’t forget to check that apache can write out log files, or it will error out. Feel free to pick a more lightweight solution to satisfy the health check (HTTP 200 response at the root URL of your service).
It goes without saying you will want to set your min instances to 1; otherwise, Cloud Run will kill the node if there’s no incoming request for 15 minutes (and frankly, there will be no requests at all, which I’ll explain in a second).
How job queueing works in Laravel is the framework serializes the jobs to Redis (or another supported destination). Then, these get read and deserialized by Horizon.
This requires the queue worker to have the same codebase as the application; otherwise, it wouldn’t be able to instantiate those jobs. So you could say a queue worker is always specific to the application it is handling jobs for.
In our case, we have a user-facing application and, because it uses the same image, we can use that application to access Horizon (given authentication/authorization to Horizon is configured correctly).
The worker service hosting Horizon is kept within the private VPC. With this configuration, we minimize the potential attack surface by locking down services that shouldn’t be exposed publicly.
With the provided instructions, you should be able to access the Horizon dashboard in your application and see at least 1 Supervisor instance (min instances: 1) keeping Horizon running and ready to handle your application jobs.
I hope this gives you another option to run your queue worker if you are already using Google Cloud Run!









