

One of the first steps when you are deploying an application with Docker Swarm or Kubernetes is to publish the image in a registry. It might not be clear why you need it, especially if you are used to deploying containers using Docker Compose. Docker Compose can build your image on the server as you deploy but Swarm or Kubernetes cannot.
Publishing the image to a registry allows for some interesting workflows. You can have the continuous integration (CI) pipeline building the image and publishing to the registry automatically. Then, you can use that same image to deploy to different environments, such as acceptance and/or production. The continuous deployment (CD) approach might vary, but usually it takes the shape of patching some YAML files to point our environment to the updated image version. It’s up to the team to decide whether or not the deployment will roll out automatically after the pipeline completes the build. I know there is a lot to unwrap, so let’s explore each part separately.
Publishing an Image
A CI/CD pipeline in the era of containers might look like this:
- Run your test suites (CI) on every commit/merge.
- Build the final Docker image with the most up-to-date version of the code and your application runtime dependencies (server libraries and/or extensions).
- Publish to a registry when tags are pushed (and after your tests pass).
- Then your pipeline might contain an extra step to automate the patching of the container files and send a pull request to your infrastructure repository with the newly published image version.
This already happens for some of our projects. In one, we have 3 applications:
- A main API
- A web app
- A customer-specific API
All these run in the same Kubernetes cluster. We have 2 environments: production and acceptance. Each environment has its own Kubernetes cluster, managed database (MySQL database server that runs on Azure), and a Redis server (Azure’s caching that implements Redis protocol).
Each of these environments has its own Git repository on GitHub containing all the YAML files of the applications/services running in the Kubernetes cluster.
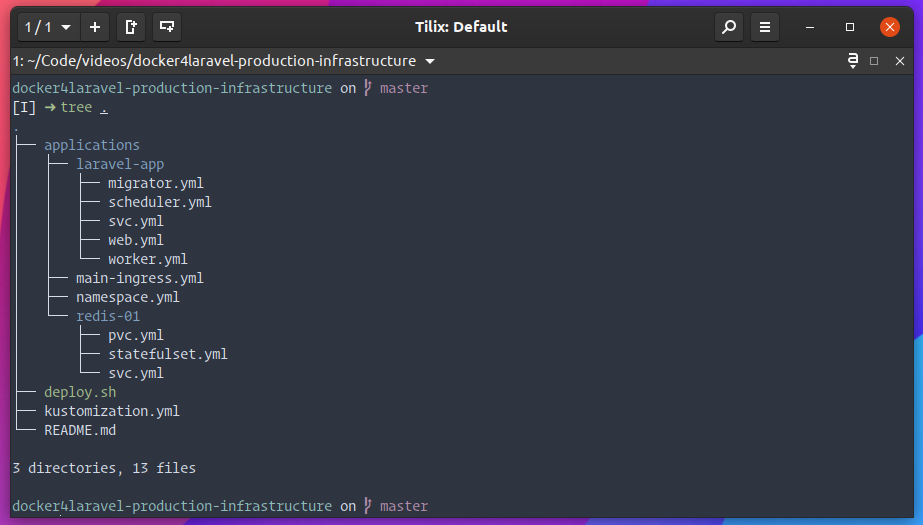
An example of an infrastructure repository of an environment.
Each application is responsible for publishing its own image to our registry, which in the case of the project I mentioned earlier, runs on Azure (not on DockerHub), but the idea is the same.
This means that each application has a build step that runs “docker build …” and then “docker push …” whenever tags are pushed to the Git repository, here’s an example:
https://gist.github.com/tonysm/fdeb123bee17790fbdff8efa1719eaee
We are making use of a GitHub action here called elgohr/Publish-Docker-Github-Action@master. The result of this workflow is a new Docker image published in our registry. But publishing the image doesn’t do anything on its own. We would have to manually update our Kubernetes Object files and change the container image to point to this newly created image.
To be honest, this is actually fine. But we can do better. Wouldn’t it be awesome if we could script this process of patching the infrastructure repository? Instead of us having to manually update the Kubernetes Object manifest file, the CI pipeline could do that for us, patch the objects with the new image and send a pull request with the same image to both environment’s infrastructure repository (acceptance and production). We could later review the pull request, maybe merge on acceptance, see how things go first and then, if we are happy, roll out the new version to production.
Well, turns out we can do exactly that.
Automating the Deployment of new images
Kustomize is a tool that allows us to better manage our Kubernetes manifests. We’re going to one feature in particular of Kustomize: images patching. Then we can use GitHub’s hub CLI tool to clone the infrastructure repository, commit the changes, and send a pull request to our infrastructure repository.
To patch our image using Kustomize, we rely on a feature that allows notation of images with tags and names. I’m not going into details, but I have published a demo repository here where you can see what I’m talking about.
Once we have that sketched out, we can then patch our image using Kustomize like this:
https://gist.github.com/tonysm/1a8d821c235bed015fd6ee5dbde4cdf7
This line assumes that we have an image named `laravel-app-nginx` in our Kustomize setup, and it will only update the Kustomization file to set the new image and tag. In our case, the image name will always be the same, so just the tag will change.
Now, we can use the hub CLI tool to commit that file to our infrastructure repository which is cloned in our CI pipeline and then submit a pull request (we can lock the main branch on it to make sure no one can push changes except us). In order to use hub we need to generate a Personal Access Token (PAT) on GitHub with the write permission in our infrastructure repository. For that, I recommend creating a machine user specifically for the project instead of using your own GitHub user. We do have a GitHub token available in our action, but that only gives permissions in the repository where the actions are running, and in our case we need programmatically push changes to another repository.
https://gist.github.com/tonysm/da8e1d45cf85ad8263465bf16b4ffc8c
The result of the script is a pull request in the infrastructure repository. In this case, we run it twice, once for each environment so you should receive something like this:
Automated Pull Requests to one of our infrastructure repositories.
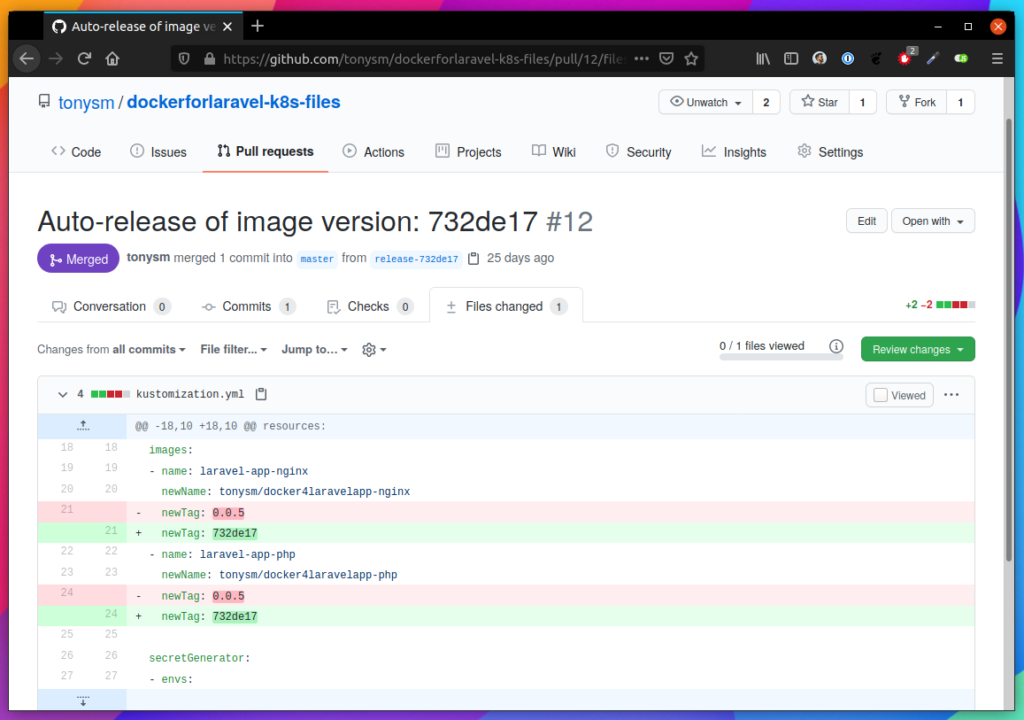
The infrastructure repositories also have its own CI/CD pipeline, and merges to the main branch (protected) are automatically applied to the correct environment (literally runs “kubectl apply -f …” in the environment from the GitHub action, see here and here).
At this point, we can merge the patch pull request with the new image, roll it out to the acceptance Kubernetes cluster, test out how the application behaves and, if we are happy with it, we can go ahead and hit the merge button in the production pull request. If we are not happy with it, we can then close the production pull request, prepare a fix in the application, which will trigger this flow again and new pull requests will be created for the new image version. Then, you can continue with this flow until you are happy for a production deployment.
Conclusion
We need to publish the Docker image to a registry, because that same image will run on different environments, on different servers. It would be a waste of resources if each server in production had to rebuild the same docker image.
That’s why we build it once and publish it in a registry so the servers only need to pull the new layers. This is pretty cool because what changes often in an application is the source code (the code you write), while the extensions that run in the container as well as your vendor libraries don’t change that often. This means that the servers will only pull the layers for the source code (when you write your docker images correctly).
It’s also important to note that this gives us the certainty that the same image version is running in acceptance and production! And we can, locally, pull the images that are being used in production for troubleshooting and try to reproduce nasty bugs or test performance.
I hope this was clear and you enjoyed the ride. Let me know what you think.









