
Lire l'article
Prochains événements
Envie de participer à l'un de nos prochains événements ? Consultez notre calendrier.
Voir le calendrierIngénierie logicielleCTO as a serviceAudits & due diligence techniqueRecrutementCoaching de CTOGestion de produit
À propos de ce service
Construisez des logiciels évolutifs et maintenables avec nos équipes d'ingénieurs expérimentées. Nous livrons du code de qualité et des bonnes pratiques pour faire réussir votre produit.
Voir ce serviceIngénierie data & IA
Faire de vos données quelque chose auquel votre produit et votre équipe peuvent se fier
Une IA prête pour la production
Des pipelines qui ne cassent pas
De l'ingénierie, pas de la magie
L'IA est un problème d'ingénierie, pas un tour de magie
La plupart des entreprises savent que des données solides sont la fondation de tout, du reporting à l'IA. Mais y arriver est dur. Nous avons vu de tout : des modèles coincés dans des notebooks Jupyter qui n'atteignent jamais la production, trop de temps passé à nettoyer des tableurs, des pipelines qui ne cessent de casser.
Du notebook à la production
Nous amenons les modèles en production, construisons des pipelines qui ne tombent pas et nettoyons la couche de données pour que votre équipe puisse se concentrer sur ce qui compte. Nous apportons les bonnes pratiques d'ingénierie pour que tout le monde puisse travailler avec.
Une vraie IA, un vrai impact
Quand vous êtes prêt·e à intégrer des LLM à votre produit ou à construire des agents IA qui font vraiment quelque chose d'utile, nous vous emmenons de « on aimerait faire quelque chose avec l'IA » à « nos clients s'appuient dessus chaque jour ». Les bonnes décisions prises tôt : architecture des données, infrastructure ML et outillage que votre équipe va réellement maintenir.
Des résultats concrets, pas seulement du code
Nous livrons des améliorations mesurables sur quatre axes clés pour votre produit et votre équipe.

Des pipelines de données qui tournent
De l'ingestion qui ne ment pas. Des pipelines qui tournent partout, pas seulement sur votre laptop. Des gates de QA qui attrapent les problèmes avant qu'ils ne contaminent votre roadmap.
Discover more
Ready to talk?
Prêt·e à arrêter de vous battre contre votre infrastructure de données ?

Machine learning classique
Quand vous avez besoin de prédiction, de classification ou de recommandation, nous vous aidons à choisir la bonne approche, construire le pipeline d'entraînement et déployer des modèles qui tournent vraiment en production.
Discover more
Ready to talk?
Envie de mettre du ML éprouvé au service de votre produit ?

Systèmes RAG & LLM
Si votre produit a besoin de connaissance en temps réel ou de retrieval intelligent sur des corpus bruts, nous construisons des systèmes RAG, des bases vectorielles, du hybrid search et des boucles d'évaluation qui tiennent hors démo.
Discover more
Ready to talk?
Envie de construire des fonctionnalités IA qui fonctionnent au-delà de la démo ?

Monitoring & détection de drift
Nous traitons la qualité du retrieval avec le même sérieux que la qualité des données : mesurable, monitorée, jamais balayée parce que le prototype avait l'air brillant.
Discover more
Ready to talk?
Envie d'avoir la certitude que vos modèles tiennent en production ?
Notre approche
“Nous apportons les bonnes pratiques d'ingénierie pour que tout le monde puisse travailler avec. En nous impliquant aux côtés de vos ingénieurs, nous transformons des données en vrac en quelque chose sur lequel on peut s'appuyer.”


Pourquoi les entreprises font appel à nous
Des modèles coincés dans des notebooks ? Des pipelines qui cassent ? Vous vous demandez comment mettre l'IA dans votre produit ? Vous n'êtes pas seul·e.
“We need to scale now.”

“We’re dealing with legacy systems nobody fully understands.”

“The madewithlove team works alongside us, treated our product with the love and attention it deserved and actively challenged us throughout the entire product development process.”
Michelle Dassen, Head of Product at Flexmail

“Our company is scaling fast, but the software isn’t.”

“We want to add AI to our product but don’t know where to start.”

“Madewithlove did a good job in our innovation lab and has built a user friendly Vick platform for school leavers.”
Paul Danneels, CIO at VDAB

“We’re stuck on an old framework version and can’t upgrade.”
“My developers are not working together.”
Clients heureux
Nous travaillons avec des entreprises qui veulent réussir leur data et leur IA. Voici comment notre approche se traduit en résultats concrets.
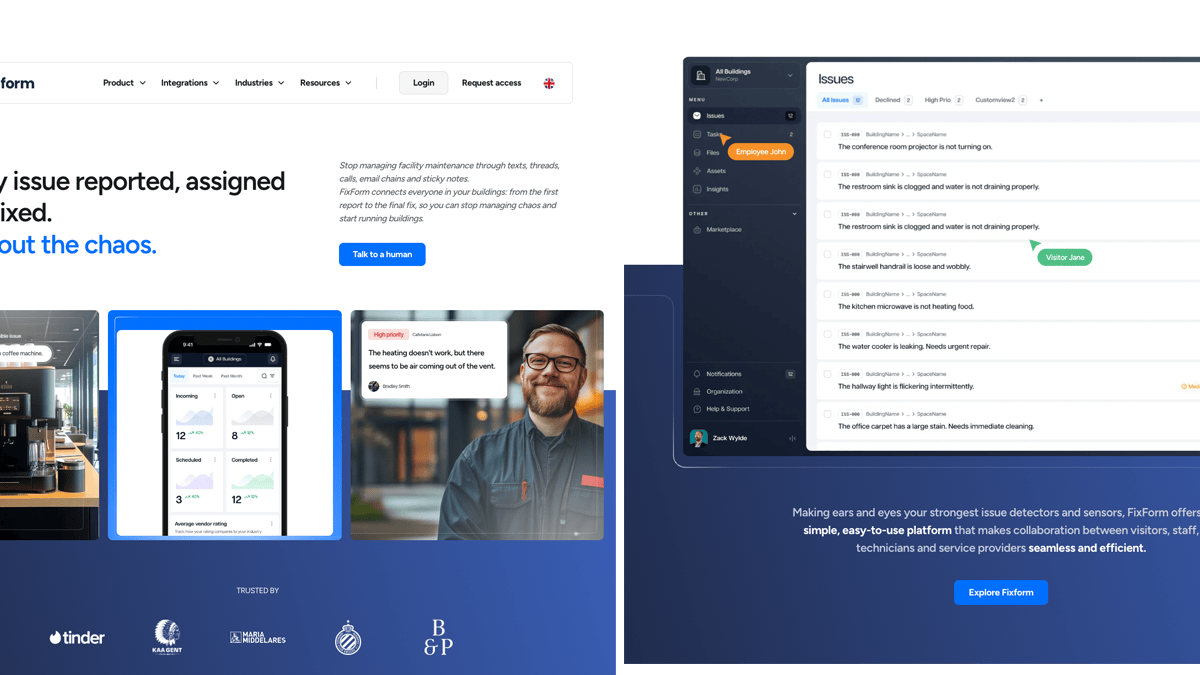
Fixform
Keeping buildings and spaces in good, safe and clean condition
After their technical co-founder departed unexpectedly, we stepped in with two staff engineers to build a quality-first MVP using Inertia.js, Vue, and Laravel. We established robust CI/CD pipelines, implemented comprehensive testing, and mentored the team through knowledge transfer.
Read case study
Nous aidons nos clients à réussir
Vous ne verrez pas des géants comme Amazon parmi nos clients. Mais vous verrez les futurs noms qui compteront dans le SaaS, parce que nous les avons aidés à anticiper les risques et à éviter l'échec.
“We couldn’t have done it without madewithlove and now realize we wouldn’t want to. I have worked with many development shops over the years and can say with 100% confidence that they truly are the best in the business.”

David Macfarlan
CEO, GearJot
“I think what I also really valued about the collaboration was transparency and knowledge transfer. It needs to be a good fit with the company and the phase that the company is in.”

Thomas Vanhumbeeck
Cofounder & CEO, FixForm
“Our internal team of developers matured a lot during the time we worked with madewithlove. Their focus on knowledge-sharing is going to help us even when madewithlove is no longer on board.”

Steven Debrauwere
CEO, Contractify
FROM 180+ SAAS AUDITS
2 in 3 SaaS teams skip code review
One engineer merges what another wrote. No second set of eyes.
The value of code reviewFROM 180+ SAAS AUDITS
40% of codebases have secrets in git
The finding investors react to hardest.
The security hole nobody talks aboutLatest insights
Nos réflexions récentes sur l'ingénierie data, l'intégration de l'IA et la construction de systèmes ML fiables (publié en anglais).
Nous pouvons vous aider sur votre data & IA
Que vous ayez besoin de construire des fonctionnalités IA fiables, de réparer votre pipeline de données, ou d'aider votre équipe à utiliser l'IA efficacement : nous sommes prêts à nous y mettre.
Questions fréquentes
Tout ce qu'il faut savoir pour travailler avec nos ingénieurs data et IA.
Non. Il faut des données suffisamment bonnes, dont la propriété est claire, qui sont comprises et monitorées. La perfection est un mythe. La prévisibilité est l'objectif.
Souvent oui. Nous identifions ce qui est récupérable, ce qui a besoin de garde-fous et ce qui doit être remplacé. La plupart des équipes ne sont pas à une réécriture du salut — elles sont à une clarification d'ownership.
Celle que votre équipe peut maintenir. Nous choisissons les outils en fonction de vos compétences, contraintes et réalité long terme — pas de la mode. Python, Airflow, Spark, Snowflake, ou quelque chose de plus simple : le logo n'est jamais le sujet.
Nous vous aidons à définir des seuils de qualité mesurables, à détecter le drift et à mettre en place des pipelines qui rendent les problèmes de données visibles, plutôt que de laisser passer silencieusement de mauvais signaux vers votre modèle.
Oui. Nous regardons votre problème, les signaux disponibles, la latence attendue, les besoins de précision et le coût. Parfois un modèle simple suffit. Parfois il faut du RAG ou de la recherche vectorielle. Parfois ni l'un ni l'autre.
En fixant des règles claires. Nous aidons les équipes à définir ce qui revient à l'IA, ce qui a besoin d'une revue humaine et comment garder une base de code cohérente quand la moitié des suggestions vient d'un modèle.
Il ingère des données de façon fiable, rejette les déchets, est reproductible de bout en bout, dispose d'un monitoring adapté et rend les échecs bruyants. S'il ne tourne que sur la machine d'un seul ingénieur, il n'est pas en bonne santé.
Oui. Nous avançons de manière incrémentale : stabiliser les données, concevoir un pipeline minimal, ajouter le monitoring et livrer les fonctionnalités par tranches fines. Il n'est pas nécessaire de tout refondre pour commencer à apporter de la valeur.
De la même façon que nous mesurons la qualité des données : avec des métriques, des tests et des boucles d'évaluation. Une démo qui marche une fois n'est pas un signal de qualité. Nous rendons le retrieval mesurable et observable.
Oui. Nous planifions notre sortie dès le premier jour. Documentation, pair programming, construction sur votre stack et transfert complet d'ownership. Pas de pipelines mystérieux. Pas de systèmes fantômes. Votre équipe continue à livrer longtemps après notre départ.