


Agentic Engineering
Agentic engineering is the frontier of AI-assisted development, or so we think. We use Claude Code, Cursor, or Copilot as coding assistants. We prompt, review the output, and iterate again. This flow works and has increased productivity, but it has also created a new bottleneck: us. With models improving at the pace they are, what does the next phase look like? I have been experimenting with building an AI agent harness that independently implements software features, and I believe this is where we are heading next.
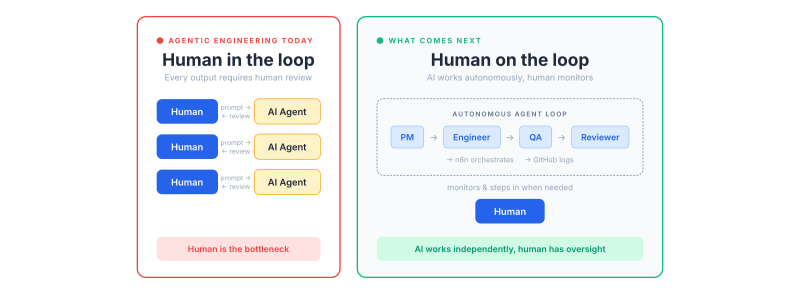
The review bottleneck
If you have been building with AI, you've probably noticed the fundamental tension. You either review every output the AI produces, or you don't. There is no comfortable middle ground. When you review everything, you end up with a maintainable system, but progress slows because human oversight becomes the bottleneck. You're essentially doing quality control on every line of code, which defeats part of the purpose of having an AI assist you in the first place.
The alternative is worse. When you skip reviews, the codebase quickly turns into a black box. You prompt and pray for the AI to create something stable. Sooner or later, the system does something you didn't expect, and you end up in an endless loop of back-and-forth with the AI, trying to fix issues without fully understanding what it built. Anyone who has tried to let an AI run unsupervised for more than a few tasks knows this feeling. The question is whether this binary choice is where we're stuck, or whether there's a way to give AI more independence without sacrificing quality.
Why orchestration can't live inside the LLM
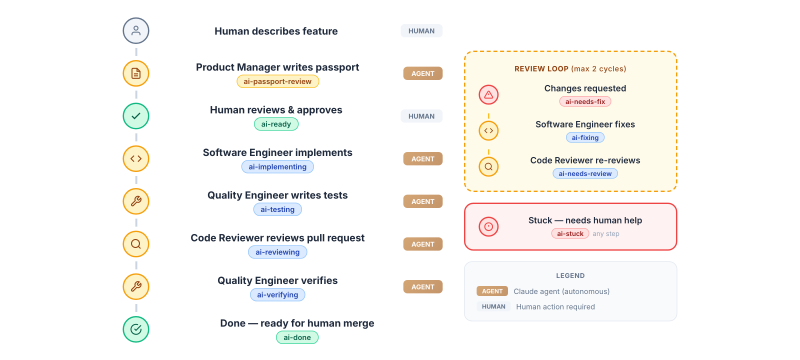
My first attempt was using Claude's team agents to create a full software development team. The idea is straightforward: you give an orchestrator agent a task, and it determines who works on what. A product manager agent writes the specification, a software engineer implements it, a quality engineer tests it, and a code reviewer signs off.
In theory, this should work. In practice, it quickly fell apart. The biggest problem was the context window. Even with Opus's large context window, agents kept forgetting the instructions I had given them to guard quality. When I asked why a specific quality check wasn't executed, I'd get the classic "Oh, I forgot!" or "I'm sorry, I missed that." Implementing a feature is a workflow, and to maintain quality throughout that workflow, you need every step to be followed consistently. The non-deterministic nature of the LLM means it sometimes follows instructions diligently and at other times just skips them. That inconsistency is a dealbreaker when you're trying to build a reliable process.
Moving the brain out of the loop
This realisation led to a key insight: if the LLM can't reliably orchestrate a workflow, something deterministic needs to. That's where n8n came in. n8n is a workflow automation tool, and it's very good at making sure the right agent is called at the right time. Instead of letting Claude decide what happens next, n8n manages the sequence whilst Claude focuses on what it's good at: thinking, writing code, and reviewing.
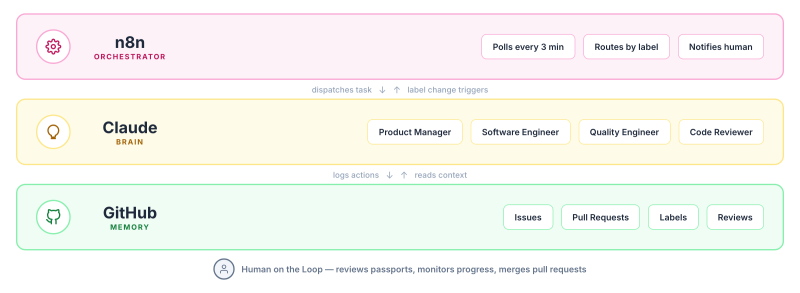
But simply chaining agents together in a linear n8n workflow creates a new problem. n8n would start the process with a trigger and run it to completion, producing an output at the finish line. There's no visibility into what happened along the way. As much as we dream of fully autonomous AI, we're not there yet. We still need to see what the AI is doing. Not to micromanage it, but to catch issues early and maintain confidence in the system.
GitHub as shared memory
How can you give AI independence whilst keeping humans informed? The answer was already sitting in front of me. When we use a Kanban board during software development, we already have a record of all actions taking place in the project. GitHub issues and pull requests are exactly this kind of system, and they became the shared memory between the AI agents and the humans overseeing the process.
Kief Morris describes this as human-on-the-loop, and that's exactly what we're building here. The human doesn't need to be in the loop, approving every action in real time. Instead, the human is on the loop, monitoring the process and stepping in only when needed. To make this work, each agent logs its actions to GitHub through labels. When an agent finishes its task, it updates the label on the issue or PR, and n8n detects the label change to trigger the next agent. The result is a system where you can always see what the AI has done, what stage the work is in, and where things might need attention, without having to sit and watch it work.
The workflow in practice
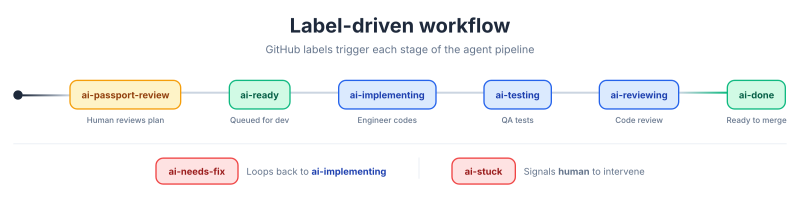
The process starts when a human describes a feature to the product manager agent. The PM agent creates a GitHub issue, writes out a feature passport, and labels it ai-passport-review. A notification goes out so a human can review the plan before development begins. This is a deliberate quality gate: the AI proposes, the human validates.
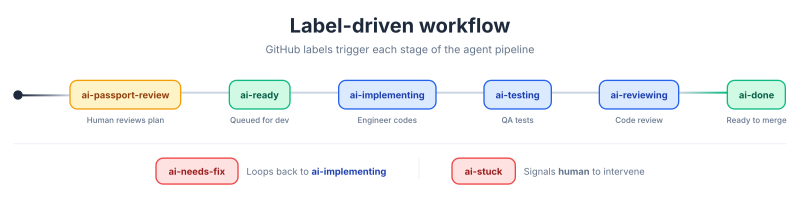
Once the human is satisfied, they swap the label to ai-ready. n8n picks up the change and hands the ticket to the software engineer agent, which implements the feature and creates a PR labelled ai-testing. The quality engineer agent then runs tests and leaves feedback as comments. If issues are found, the label changes to ai-needs-fix and the software engineer picks it up again. When testing passes, the code reviewer agent does a final review and either sends it back for fixes or marks it ai-done. Throughout this flow, there's an ai-stuck label as a safety valve: when something goes wrong that the agents can't resolve, it signals a human to step in.
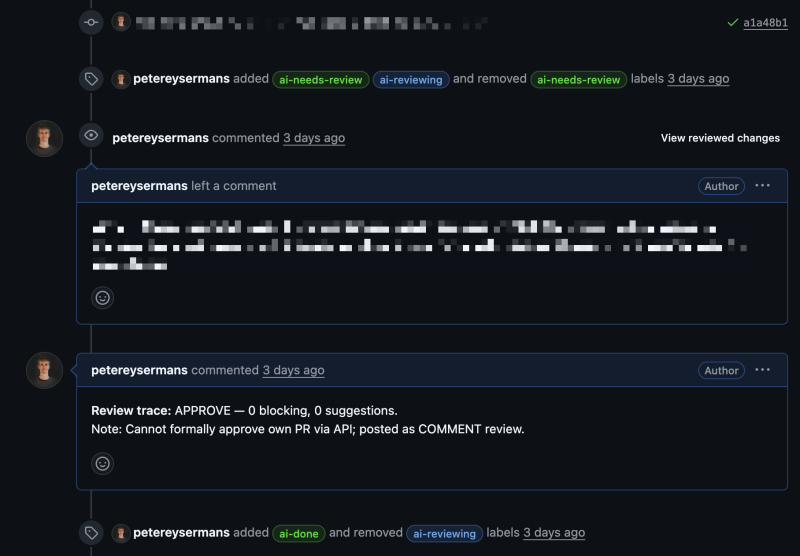
What makes this work is that every action is visible. The GitHub board becomes the project's memory, shared between AI and humans. You can check in once a day, scroll through the activity, and know exactly what happened without having been there for every step.
What comes next
This is still an early step. The system isn't perfect, and there are plenty of rough edges to smooth out. But I believe this direction, deterministic orchestration with AI agents that log their work to a shared system, is where the industry is heading. The agentic engineering we do today, prompting Claude or Copilot as an assistant, is the current ceiling. Where it's going is toward agent harnesses you can plug into a repository, which independently implement the tickets you mark as ready.
The real productivity gain won't come from making humans review faster. That bottleneck will always exist to some degree. It will come from building robust systems with enough quality gates so that the end result is consistently close to what we, as humans, would consider good work. The human stays on the loop, not in it. That's the difference between assisting engineers and multiplying their output.









